Introduction to web scraping with Node.js
Introduction To Web Scraping With Node JS. Web Scraping comes in, when we’re in a need to collect information from different web pages
For a long time when ever I wanted to try and create websites for practice I would visit a website, open the console and try to get the content I needed - all this to avoid using lorem ipsum, which I absolutely hate.
Few months a go I heard of web scraping, hey better late the never right? And it seems to do a similar thing to what I tried to do manually.
Today I’m going to explain how to web scrape with Node.
Setting up
We’ll be using three packages to accomplish this.
- Axios is a “promise based HTTP client for the browser and node.js” and we’ll use it to get html from any chosen website.
- Cheerio is like jQuery but for the server. We’ll use it as a way to pick content from the Axios results.
- fs is a node module which we’ll use to write the fetched content into a JSON file.
Let’s start setting up the project. First create a folder, then cd to it in the terminal.
To initialise the project just run npm init and follow the steps (you can just hit enter to everything). When the initial setup is complete you’ll have created a package.json file.
Now we need to install the two packages we listed above
npm install --save axios cheerio(Remember fs is already part of node, we do not need to install anything for it)
You’ll see that the above packages are installed under node_modules directory, they are also listed inside the package.json file.
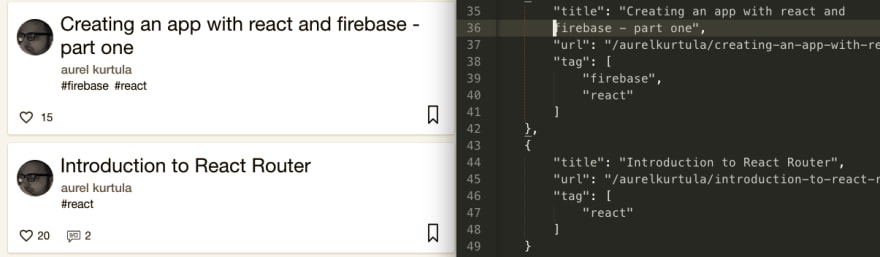
Our mission is to get the posts we’ve written and store them in a JSON file, as you see below:
Create a JavaScript file in your project folder, call it devtoList.js if you like.
First require the packages we installed
let axios = require('axios');
let cheerio = require('cheerio');
let fs = require('fs'); Now lets get the contents from dev.to
axios.get('https://dev.to/aurelkurtula')
.then((response) => {
if(response.status === 200) {
const html = response.data;
const $ = cheerio.load(html);
}
}, (error) => console.log(err) );
In the first line we get the contents from the specified URL. As already stated, axios is promise based, then we check if the response was correct, and get the data.
If you console log response.data you’ll see the html markup from the url. Then we load that HTML into cheerio (jQuery would do this for us behind the scenes). To drive the point home let’s replace response.data with hard-coded html
const html = '<h3 class="title">I have a bunch of questions on how to behave when contributing to open source</h3>'
const h3 = cheerio.load(html)
console.log(h3.text())That returns the string without the h3 tag.
Select the content
At this point you would open the console on the website you want to scrape and find the content you need. Here it is:

From the above we know that every article has the class of single-article, The title is an h3 tag and the tags are inside a tags class.
axios.get('https://dev.to/aurelkurtula')
.then((response) => {
if(response.status === 200) {
const html = response.data;
const $ = cheerio.load(html);
let devtoList = [];
$('.single-article').each(function(i, elem) {
devtoList[i] = {
title: $(this).find('h3').text().trim(),
url: $(this).children('.index-article-link').attr('href'),
tags: $(this).find('.tags').text().split('#')
.map(tag =>tag.trim())
.filter(function(n){ return n != "" })
}
});
}
}, (error) => console.log(err) );
The above code is very easy to read, especially if we refer to the screenshot above. We loop through each node with the class of .single-article. Then we find the only h3, we get the text from it and just trim() the redundant white space. Then the url is just as simple, we get the href from the relevant anchor tag.
Getting the tags is just simple really. We first get them all as a string (#tag1 #tag2) then we split that string (whenever # appears) into an array. Finally we map through each value in the array just to trim() the white space, finally we filter out the any empty values (mostly caused by the trimming).
The declaration of an empty array (let devtoList = []) outside the loop allows us to populate it from within.
That would be it. The devtoList array object has the data we scraped from the website. Now we just want to store this data into a JSON file so that we can use it elsewhere.
axios.get('https://dev.to/aurelkurtula')
.then((response) => {
if(response.status === 200) {
const html = response.data;
const $ = cheerio.load(html);
let devtoList = [];
$('.single-article').each(function(i, elem) {
devtoList[i] = {
title: $(this).find('h3').text().trim(),
url: $(this).children('.index-article-link').attr('href'),
tags: $(this).find('.tags').text().split('#')
.map(tag =>tag.trim())
.filter(function(n){ return n != "" })
}
});
const devtoListTrimmed = devtoList.filter(n => n != undefined )
fs.writeFile('devtoList.json',
JSON.stringify(devtoListTrimmed, null, 4),
(err)=> console.log('File successfully written!'))
}
}, (error) => console.log(err) );
The original devtoList array object might have empty values, so we just trim them away, then we use the fs module to write to a file (above I named it devtoList.json, the content of which the array object converted into JSON.
And that’s all it takes!
The code above can be found in github
#node-js #javascript