1. Introduction
If you have been following the recent developments in the NLP space, then it would be almost impossible to avoid the GPT-3 hype in the last few months. It all started with researchers in OpenAl researchers publishing their paper “Language Models are few Shot Learners” which introduced the GPT-3 family of models.
GPT-3’s size and language capabilities are breathtaking, it can create fiction, develop program code, compose thoughtful business memos, summarize text and much more. Its possible use cases are limited only by our imaginations. What makes it fascinating is that the same algorithm can perform a wide range of tasks. At the same time there is widespread misunderstanding about the nature and risks of GPT-3’s abilities.
To better appreciate the powers and limitations of GPT-3, one needs some familiarity with pre-trained NLP models which came before it. Table below compares some of the prominent pre-trained models:
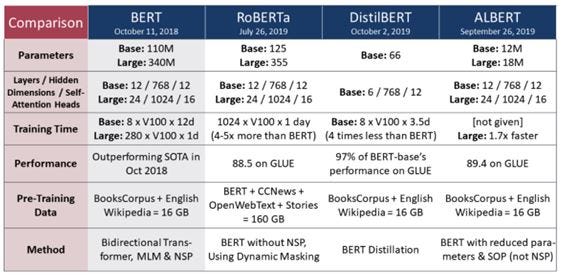
Let’s look at some of the common characteristics of the pre-trained NLP models before GPT-3:
i) NLP Pre-Trained models are based on Transformer Architecture
Most of the pre-trained models belong to the Transformer family that use Attention techniques;These models can be divided into four categories:
#language-model #machine-learning #gpt-3 #artificial-intelligence #nlp
