KNN is a non-parametric and lazy learning algorithm. Non-parametric means there is no assumption for underlying data distribution. In other words, the model structure determined from the dataset. This will be very helpful in practice where most of the real-world datasets do not follow mathematical theoretical assumptions.
KNN is one of the most simple and traditional non-parametric techniques to classify samples. Given an input vector, KNN calculates the approximate distances between the vectors and then assign the points which are not yet labeled to the class of its K-nearest neighbors.
The lazy algorithm means it does not need any training data points for model generation. All training data used in the testing phase. This makes training faster and the testing phase slower and costlier. The costly testing phase means time and memory. In the worst case, KNN needs more time to scan all data points, and scanning all data points will require more memory for storing training data.
K-NN for classification
Classification is a type of supervised learning. It specifies the class to which data elements belong to and is best used when the output has finite and discrete values. It predicts a class for an input variable as well.
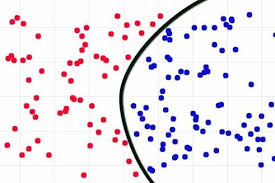
Consider given review is positive (or) Negative, classification is all about if we give a new query points determine (or) predict the given review is positive (or) Negative.
Classification is all about learning the function for given points.
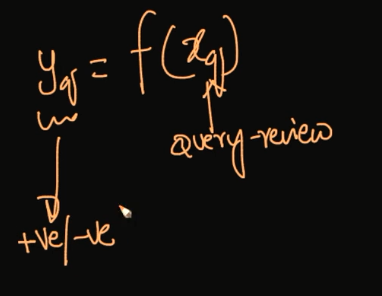
How does the K-NN algorithm work?
In K-NN, K is the number of nearest neighbors. The number of neighbors is the core deciding factor. K is generally an odd number if the number of classes is 2. When K=1, then the algorithm is known as the nearest neighbor algorithm. This is the simplest case. Suppose P1 is the point, for which label needs to predict. First, you find the one closest point to P1 and then the label of the nearest point assigned to P1.
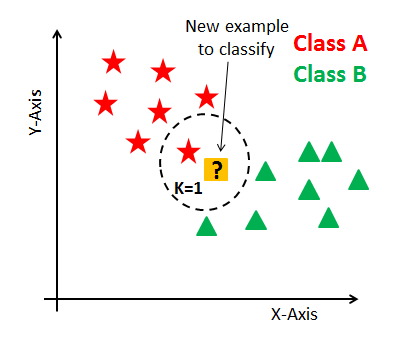
Suppose P1 is the point, for which label needs to predict. First, you find the k closest point to P1 and then classify points by majority vote of its k neighbors. Each object votes for their class and the class with the most votes is taken as the prediction. For finding closest similar points, you find the distance between points using distance measures such as Euclidean distance, Hamming distance, Manhattan distance, and Minkowski distance.
K-NN has the following basic steps:
- Calculate distance
- Find closest neighbors
- Vote for labels
- Take the majority Vote
Failure Cases of K-NN:
_1.When Query Point is far away from the data points.

2.If we have Jumble data sets.

For the above image shows jumble sets of data set, no useful information in the above data set. In this situation, the algorithm may be failing.
_Distance Measures in K-NN: _There are mainly four distance measures in Machine Learning Listed below.
- Euclidean Distance
- Manhattan Distance
- Minkowski Distance
- Hamming Distance
Euclidean Distance
The Euclidean distance between two points in either the plane or 3-dimensional space measures the length of a segment connecting the two points. It is the most obvious way of representing distance between two points. Euclidean distance marks the shortest route of the two points.
The Pythagorean Theorem can be used to calculate the distance between two points, as shown in the figure below. If the points (x1,y1)(x1,y1) and (x2,y2)(x2,y2) are in 2-dimensional space, then the Euclidean distance between them is
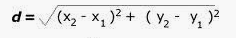
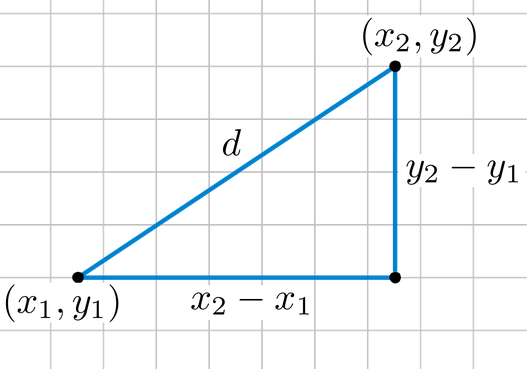
Euclidean distance is called an L2 Norm of a vector.
Norm means the distance between two vectors.
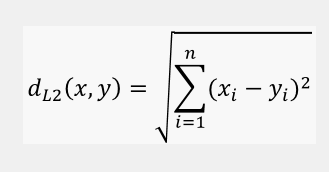
Euclidean distance from an origin is given by
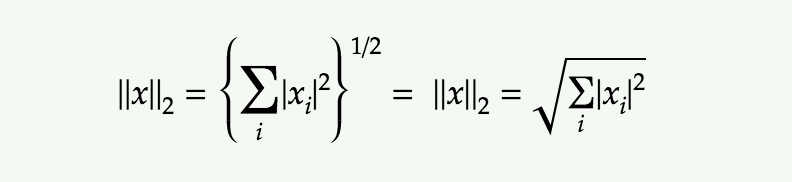
Manhattan Distance
The Manhattan distance between two vectors (city blocks) is equal to the one-norm of the distance between the vectors. The distance function (also called a “metric”) involved is also called the “taxi cab” metric.
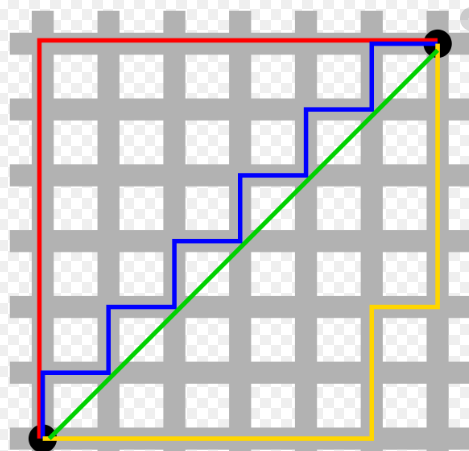
Manhattan distance between two vectors is called as L1 Norm of a vector.
In L2 Norm we take the sum of the Squaring of the difference between elements vectors, in L1 Norm we take the sum of the absolute difference between elements vectors.
Manhattan Distance between two points (x1, y1) and (x2, y2) is:
|x1 — x2| + |y1 — y2|.
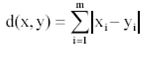
Manhattan Distance****from an origin is given by
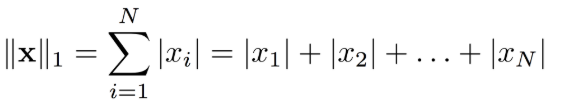
Minkowski Distance
Minkowski distance__is a metric in a normed vector space. Minkowski distance is used for distance similarity of vector. Given two or more vectors, find distance similarity of these vectors.
#analytics #machine-learning #applied-ai #data-science #k-nearest-neighbors #data analytic
