Dirty data leads to bad model quality. In real-world NLP problems we often meet texts with a lot of typos. As the result, we are unable to reach the best score. As painful as it may be, data should be cleaned before fitting.
We need an automatic spelling corrector which can fix words with typos and, at the same time not break correct spellings.
But how can we achieve this?
Let start with a Norvig’s spelling corrector and iteratively increase its capabilities.
Norvig’s approach
Peter Norvig (director of research at Google) described the following approach to spelling correction.
Let’s take a word and brute force all possible edits, such as delete, insert, transpose, replace and split. Eg. for word abc possible candidates will be: ab ac bc bac cba acb a_bc ab_c aabc abbc acbc adbc aebc etc.
Every word is added to a candidate list. We repeat this procedure for every word for a second time to get candidates with bigger edit distance (for cases with two errors).
Each candidate is estimated with unigram language model. For each vocabulary word frequencies are pre-calculated, based on some big text collections. The candidate word with highest frequency is taken as an answer.
Adding some context
First improvement — adding n-gram language model (3-grams). Let’s pre-calculate not only single words, but word and a small context (3 nearest words). Let’s estimate probability of some fragment as a product of all n-grams of n-size:
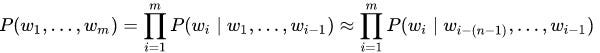
To make everything simple let’s calculate probability of n-gram of size n as a product of probabilities of all lower order grams (actually there are some smoothing technics, like Kneser–Ney — they improve model’s accuracy, but let’s talk about it later, see “Improve Accuracy” paragraph below):
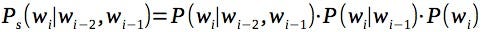
To get a probability of n-gram from appearance frequencies we need to normalize frequencies (eg. divide number of 3-grams by number of 2-grams, etc.):
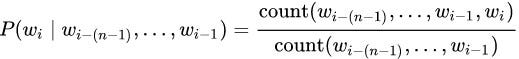
Now we can use our extended language model to estimate candidates with context.
#spelling-correction #data-preprocessing #nlp #data-science #python
