The attention mechanism is generally used to improve the performance of seq2seq or encoder-decoder architecture. The principle of the attention mechanism is to calculate the correlation between query and each key to obtain the attention distribution weight. In most NLP tasks, the key and value are the encoding of the input sequence.
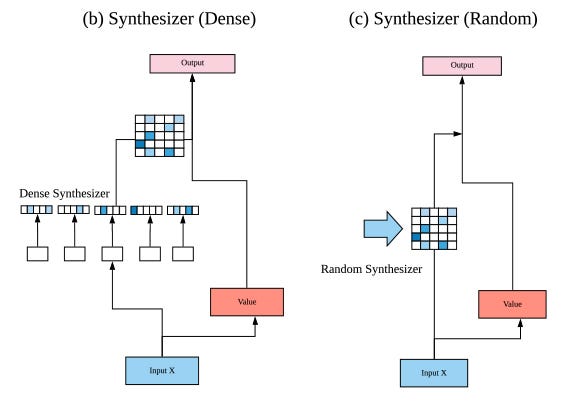
[4] studies the real importance and contribution of the dot product-based self-attention mechanism to the performance of the Transformer model.Through experiments, it was found that the random array matrix unexpectedly performed quite competitively, and learning the weight of attention from token to token (query-key) interaction is not so important.
To this end, they propose SYNTHESIZER, a model that can learn comprehensive attention weights without the need for **token-to-token **interaction.
Basic Concepts
Here we focus on how the basic Self-Attention mechanism works, which is the first layer of the Transformers model. Essentially, for each input vector, Self-Attention produces a vector that is weighted and summed over its neighbours, where the weight is determined by the relationship or connectivity between words.
At the most basic level, Self-Attention is a process in which one vector sequence x is encoded into another vector sequence z . Each original vector is just a block representing a word.The direction of each word vector is meaningful. The similarity and difference between the vectors correspond to the similarity and difference of the words themselves. Its corresponding z vector represents both the original word and its relationship with other words around it.
First, we multiply the vector x by all the vectors in a sequence, including itself. You can think of the dot product of two vectors as a measure of how similar they are.
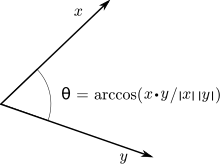
The dot product of two vectors is proportional to the cosine of the angle between them , so the closer they are in direction, the larger the dot product.
We need to normalize them so that they are easier to use. We will use the Softmax formula to achieve this. This converts the sequence of numbers to a range of 0, 1, where each output is proportional to the exponent of the input number. This makes our weights easier to use and interpret.
Now we take the normalized weights , multiply them with the x input vector, and add their products, we get an output z vector.
Transformer Self-Attention
In transformer self-attention, each word has 3 different vectors, they are Query vector (Q), Key vector (K) and Value vector (V).

They are obtained by multiplying the embedding vector x by three different weight matrices W^ Q , W^ K, W^ V by using three different weight matrices.
#attention-mechanism #deep-learning #transformers #nlp #deep learning