Hello everyone! I wanna share about movies recommeder system with one of modeling its collaborative filtering. Before we go to our dataset, let’s see why we need recommender system?
First, some people might have been confused about choosing a movie to watch. Recommender system, like we know it would be give you recommend movie based on the movie you have watched. The recommender system would be give you recommendation by genre, cast, director, rating movie from that you have been done and many more. Simply, like you watching youtube and the next video _recommendation _would be coming to you after you watching that video. The machine would be learning about what you like and that you watch frequently maybe based on “genre” or “type” of that videos and many more information about that videos.
A recommender system or a recommendation system (sometimes replacing ‘system’ with a synonym such as platform or engine) is a subclass of information filtering system that seeks to predict the **“rating” or “preference”** a user would give to an item. They are primarily used in commercial applications. — Wikipedia
There is four types of recommender system that I know.
- Demographic Filtering
- Decide on the metric or score to rate items on.
- Calculate the score for every item
- Sort the item based on the score and output the top results
- Its offers generalized recommnendations to every user, not personalized recommendation
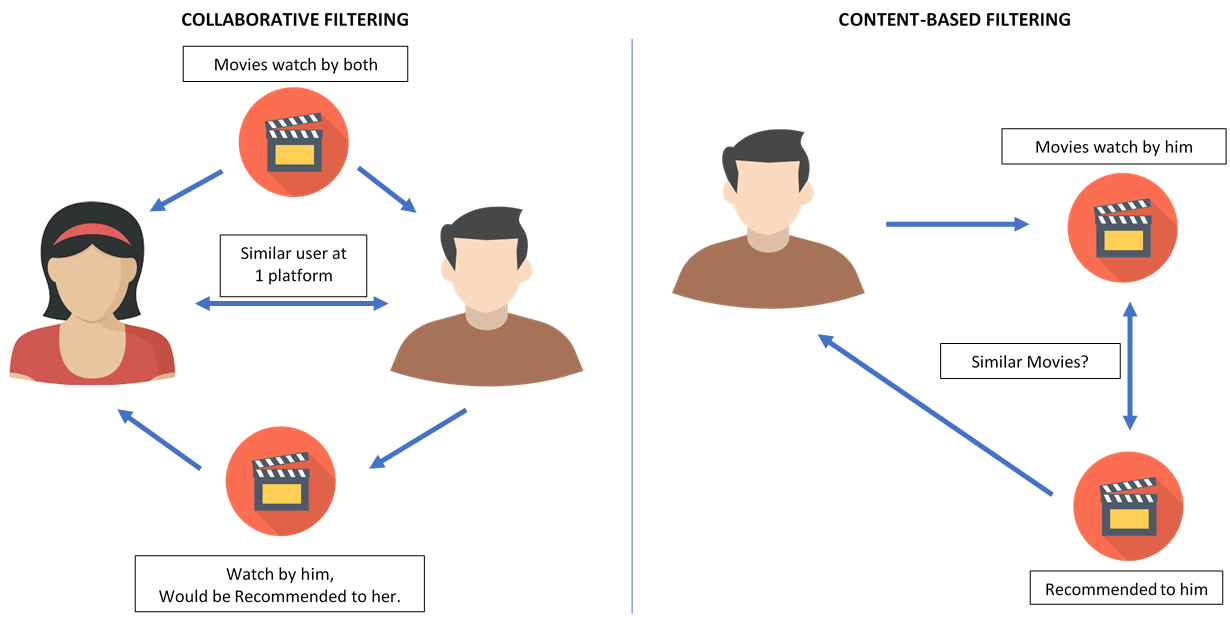
Difference between content based filtering and collaborative filtering
2. Content Based Filtering
Content-based filtering uses item features to recommend other items similar to what the user likes, based on their previous actions or explicit feedback
3. Collaborative Filtering
Collaborative filtering is based on the assumption that people who agreed in the past will agree in the future, and that they will like similar kinds of items as they liked in the past.
4. Hybrid
Called _“Hybrid” _cause recommender system with hybrid is combination between collaborative filtering and content based filtering.
Exploratory Data Analysis
This dataset, I take from kaggle but really sorry the source (url) has been down, maybe this link or dataset has been deleted by that user. This dataset it’s about every movie in IMDB until first quarter in 2018. This is dataframe info for the first csv.
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 45466 entries, 0 to 45465
Data columns (total 24 columns):
## Column Non-Null Count Dtype
--- ------ -------------- -----
0 adult 45466 non-null object
1 belongs_to_collection 4494 non-null object
2 budget 45466 non-null object
3 genres 45466 non-null object
4 homepage 7782 non-null object
5 id 45466 non-null object
6 imdb_id 45449 non-null object
7 original_language 45455 non-null object
8 original_title 45466 non-null object
9 overview 44512 non-null object
10 popularity 45461 non-null object
11 poster_path 45080 non-null object
12 production_companies 45463 non-null object
13 production_countries 45463 non-null object
14 release_date 45379 non-null object
15 revenue 45460 non-null float64
16 runtime 45203 non-null float64
17 spoken_languages 45460 non-null object
18 status 45379 non-null object
19 tagline 20412 non-null object
20 title 45460 non-null object
21 video 45460 non-null object
22 vote_average 45460 non-null float64
23 vote_count 45460 non-null float64
I’ll try combine csv dataset to build the model, there is the final dataset would be train to our model.
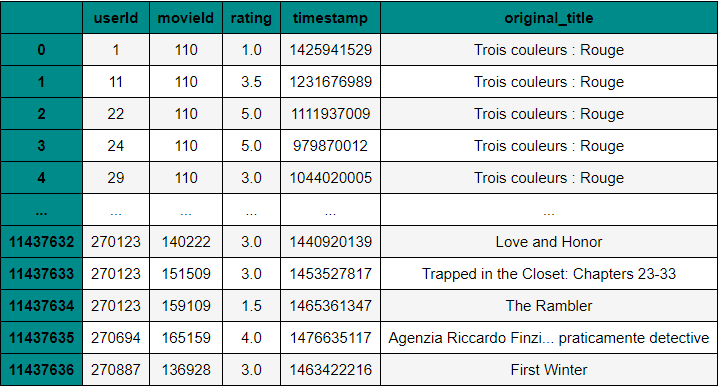
Combine some dataframe, one userId may give some movie in this dataset.
I’ll try to cleaning this dataset and make some exploratory data analysis for this dataset. Let’s see what we can take some insight there.
#recommendation-system #machine-learning #data-science #recommender-systems #surpriselib #deep learning
