Introduction
Due to the development of Big Data during the last decade. organizations are now faced with analysing large amounts of data coming from a wide variety of sources on a daily basis.
Natural Language Processing (NLP) is the area of research in Artificial Intelligence focused on processing and using Text and Speech data to create smart machines and create insights.
One of nowadays most interesting NLP application is creating machines able to discuss with humans about complex topics. IBM Project Debater represents so far one of the most successful approaches in this area.
Preprocessing Techniques
Some of the most common techniques which are applied in order to prepare text data for inference are:
- **Tokenization: **is used to segment the input text into its constituents words (tokens). In this way, it becomes easier to then convert our data into a numerical format.
- **Stop Words Removal: **is applied in order to remove from our text all the prepositions (eg. “an”, “the”, etc…) which can just be considered as a source of noise in our data (since they do not carry additional informative information in our data).
- **Stemming: **is finally used in order to get rid of all the affixes in our data (eg. prefixes or suffixes). In this way, it can in fact become much easier for our algorithm to not consider as distinguished words which have actually similar meaning (eg. insight ~ insightful).
All of these preprocessing techniques can be easily applied to different types of texts using standard Python NLP libraries such as NLTK and Spacy.
Additionally, in order to extrapolate the language syntax and structure of our text, we can make use of techniques such as Parts of Speech (POS) Tagging and Shallow Parsing (Figure 1). Using these techniques, in fact, we explicitly tag each word with its lexical category (which is based on the phrase syntactic context).
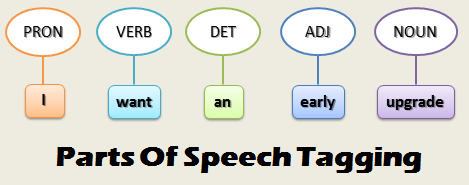
Figure 1: Parts of Speech Tagging Example [1].
Modelling Techniques
Bag of Words
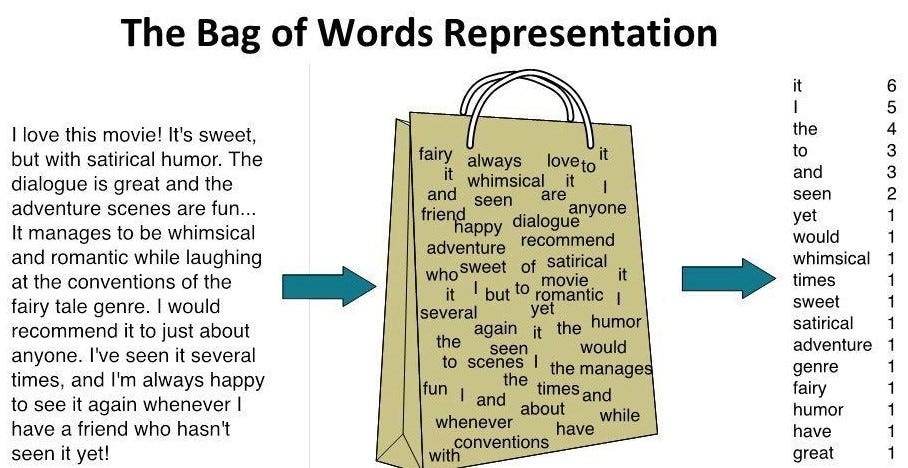
Bag of Words is a technique used in Natural Language Processing and Computer Vision in order to create new features for training classifiers (Figure 2). This technique is implemented by constructing a histogram counting all the words in our document (not taking into account the word order and syntax rules).
#machine-learning #towards-data-science #technology #data-science #artificial-intelligence