The term Transfer Learning refers to the leverage of knowledge gained by a Neural Network trained on a certain (usually large) available dataset for solving new tasks for which few training examples are available, integrating the existing knowledge with the new one learned from the few examples of the task-specific dataset. Transfer Learning is thus commonly used, often together with other techniques such as Data Augmentation, in order to address the problem of lack of training data.
But, in practice, how much can Transfer Learning actually help, and how many training examples do we really need in order for it to be effective?
In this story, I try to answer these questions by applying two Transfer Learning techniques (e.g. Feature Extraction and Fine-Tuning) for addressing an Image Classification task, varying the number of examples on which the models are trained in order to see how the lack of data affects the effectiveness of the adopted approaches.
Experimental Case Study
The task chosen for experimenting Transfer Learning consists of the classification of flower images into 102 different categories. The choice of this task is mainly due to the easy availability of a flowers dataset, as well as to the domain of the problem, which is generic enough to be suitable for effectively applying Transfer Learning with neural networks pre-trained on the well-known ImageNet dataset.
The adopted dataset is the 102 Category Flower Dataset created by M. Nilsback and A. Zisserman [3], which is a collection of 8189 labelled flowers images belonging to 102 different classes. For each class, there are between 40 and 258 instances and all the dataset images have significant scale, pose and light variations. The detailed list of the 102 categories together with the respective number of instances is available here.

Figure 1: Examples of images extracted from the 102 Category Dataset.
In order to create training datasets of different sizes and evaluate how they affect the performance of the trained networks, the original set of flowers images is split into training, validation and test sets several times, each time adopting different split percentages. Specifically, three different training sets are created (that from now on will be referred to as the Large, Medium and Small training sets) using the percentages shown in the table below.

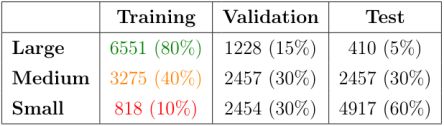
Table 1: number of examples and split percentages (referred to the complete unpartitioned flowers dataset) of the datasets used to perform the experiments.
All the splits are performed adopting stratified sampling, in order to avoid introducing sampling biases and ensuring in this way that all the obtained training, validation and test subsets are representative of the whole initial set of images.
Adopted strategies
The image classification task described above is addressed by adopting the two popular techniques that are commonly used when applying Transfer Learning with pre-trained CNNs, namely Feature Extraction and Fine-Tuning.
Feature Extraction
Feature Extraction basically consists of taking the convolutional base of a previously trained network, running the target data through it and training a new classifier on top of the output, as summarized in the figure below.
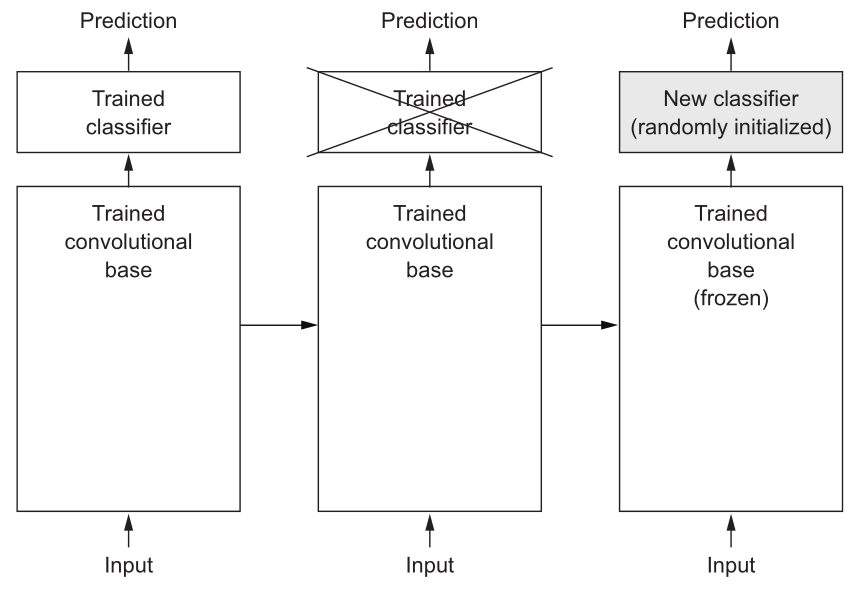
Figure 2: Feature Extraction applied to a convolutional neural network: the classifiers are swapped while the same convolutional base is kept. “Frozen” means that the weighs are not updated during training.
The classifier stacked on top of the convolutional base can either be a stack of fully-connected layers or just a single Global Pooling layer, both followed by Dense layer with softmax activation function. There is no specific rule regarding which kind of classifier should be adopted, but, as described by Lin et. al [2], using just a single Global Pooling layer generally leads to less overfitting since in this layer there are no parameters to optimize.
Consequently, since the training sets used in the experiments are relatively small, the chosen classifier only consists of a single Global Average Pooling layer which output is fed directly into a softmax activated layer that outputs the probabilities for each of the 102 flowers categories.
During the training, only the weights of the top classifiers are updated, while the weights of the convolutional base are “frozen” and thus kept unchanged.
In this way, the shallow classifier learns how to classify the flower images into the possible 102 categories from the off-the-shelf representations previously learned by the source model for its domain. If the source and the target domains are similar, then these representations are likely to be useful to the classifier and the transferred knowledge can thus bring an improvement to its performance once it is trained.
Fine-Tuning
Fine-Tuning can be seen as a further step than Feature Extraction that consists of selectively retraining some of the top layers of the convolutional base previously used for extracting features. In this way, the more abstract representations of the source model learned by its last layers are slightly adjusted to make them more relevant for the target problem.
This can be achieved by unfreezing some of the top layers of the convolutional base, keeping frozen all its other layers and jointly training the convolutional base with the same classifier previously used for Feature Extraction, as represented in the figure below.
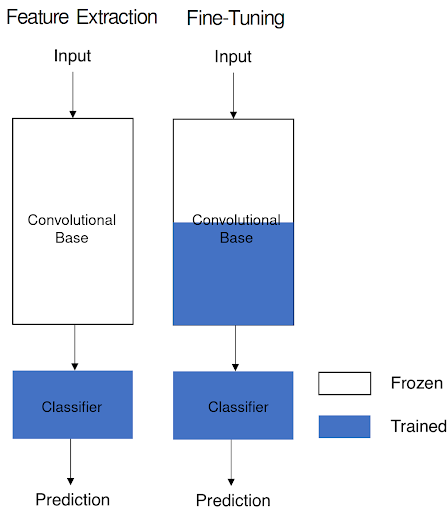
Figure 3: Feature Extraction compared to Fine-Tuning.
It is important to point out that, according to F. Chollet, the top layers of a pre-trained convolutional base can be fine-tuned only if the classifier on top of it has already been previously trained. The reason is that if the classifier was not already trained, then its weights would be randomly initialized. As a consequence, the error signal propagating through the network during training would be too large and the unfrozen weights would be updated disrupting the abstract representations previously learned by the convolutional base.
#deep-learning #machine-learning #artificial-intelligence #image-classification #transfer-learning #deep learning