How two critical issues could be explored and solved at the same time?
- The first one is as old as employment is: people deciding to leave their employer for a better(?) job.
- The second has appeared over the last years: being able to explain - in an understandable way - how extremely complex A.I. models are making predictions.
To explore these two problems, we will need a couple of tools and data:
- As there is no real dataset publicly shared regarding employees’ resignation, we will use the one created by the IBM Data Science team to promote Watson. It is available here on Kaggle.
- The code and notebook used in this article (link at the end) were created with Google Colab. This is a great resource for developers, providing GPU and TPU access at no cost with up-to-date Python libraries and the possibility to install “exotic” packages when needed.
- Google Colab does embed a lot of Python packages but we will need to install CatBoost (our Classifier) and SHAP (our Explainer):
!pip install shap
!pip install catboost
Data Exploration
After importing the libraries required for this use-case, we can observe that the dataset is composed of 1470 entries, with 9 categorical features and 25 numerical ones.
import pandas as pd
from imblearn.under_sampling import ClusterCentroids
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
from catboost import CatBoostClassifier
import shap
## The following lines should be used only on Google Colab
## to connect to your Google Drive
from google.colab import drive
drive.mount('/content/drive')
The 9th column “EmployeeNumber” is unique for each employee so we will use it as an index for our Pandas dataframe. This instruction is passed thanks to “index_col=9” when reading the CSV file:
df = pd.read_csv("./WA_Fn-UseC_-HR-Employee-Attrition.csv", index_col=9)
df.info()
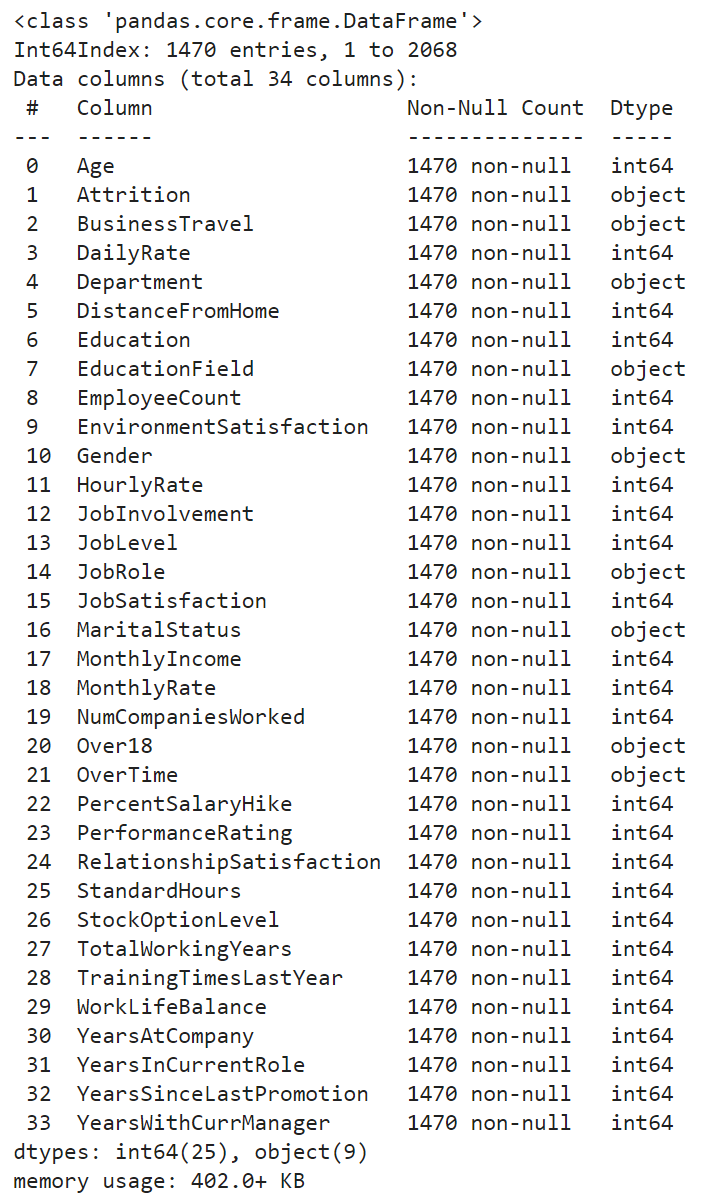
There is no missing information within the whole dataset… this is clearly a synthetic one 😅.
#shap #machine-learning #catboost #python #data-science

3.85 GEEK