In one of my previous posts, I took you through the steps that I performed to preprocess Criteo dataset used for prediction of the click through rate on Ads. I also trained ML models to predict labels on the testing data set. You can find the post here.
In this post, I will be taking you through the steps that I performed to simulate the process of ML models predicting labels on streaming data.
When you go through the mentioned post, you will find that I used pyspark on DataBricks notebooks to preprocess the Criteo data. I split the preprocessed data into training set and testing set. In order to export the test data to my local machine as a single parquet file, first I saved the training set in the FileStore in one partition as one file using dataFrameName.coalesce(1).write.

I used mleap to export my trained models as a zip file. In order to use mleap, I had to install mleap-spark from maven, mleap from pypi, and mlflow. Then, I copied the model to the FileStore so I can download to my local machine.

Make sure that the version of the mleap-pypi version matches the mleap-maven version. For learning the version of the mleap-pypi installed on DataBricks , you can do the following:


You can learn out the version of the mleap-maven version by looking through the coordinates e.g. ml.combust.mleap:mleap-spark_2.11:0.16.0.
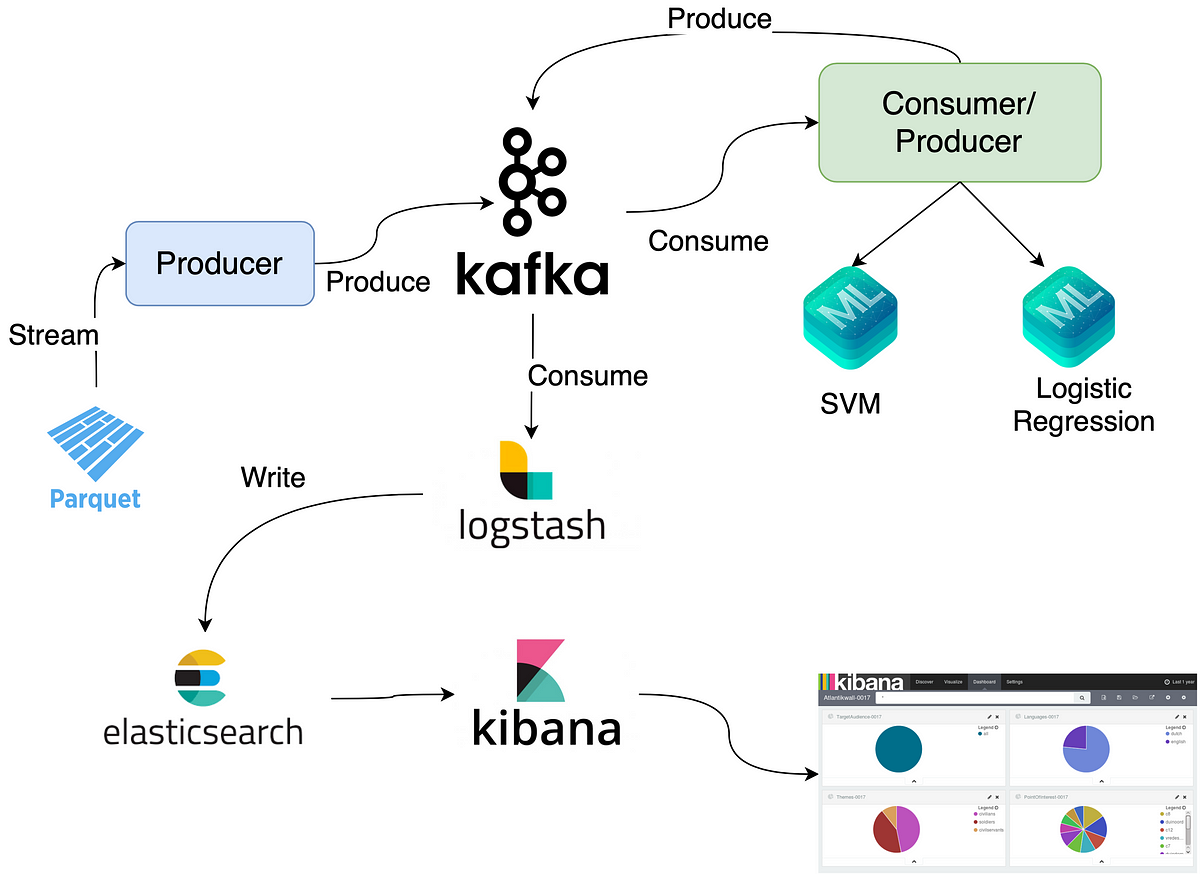
After downloading my models and the testing dataset on my local machine, I had a docker compose up running with Kafka, Zookeeper, Logstash, Elasticsearch and Kibana.
I Developed a producer where I used “pyarrow” library to read the parquet file that has the test dataset. The producer then sends the label (class decision) and the features column to Kafka in a streaming fashion.
#kibana #streaming #kafka #elasticsearch #logstash #data-science