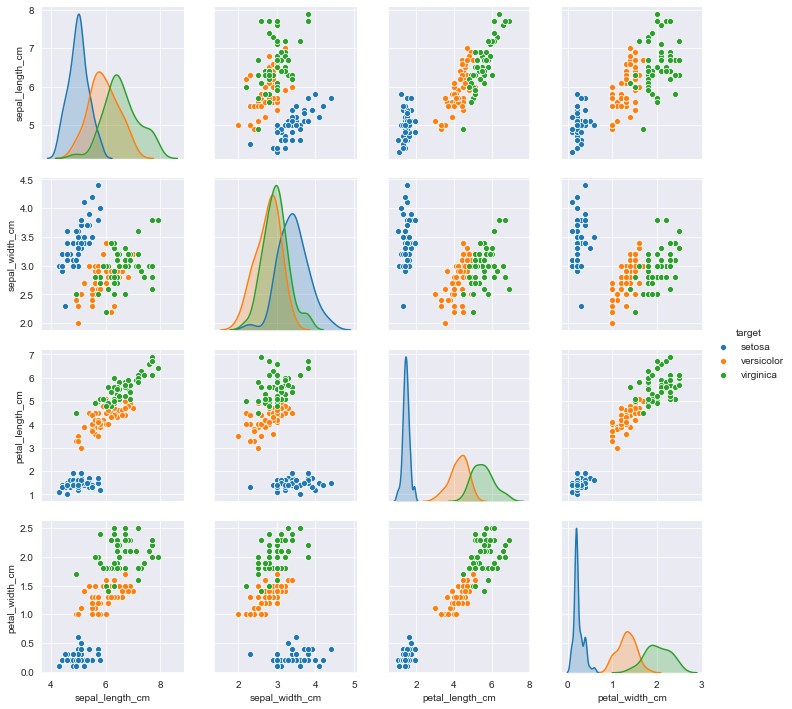
This article contains in-depth algorithm overviews of the K-Nearest Neighbors algorithm (Classification and Regression) as well as the following Model Validation techniques: Traditional Train/Test Split and Repeated K-Fold Cross Validation. The algorithm overviews include detailed descriptions of the methodologies and mathematics that occur internally with accompanying concrete examples. Also included are custom, fully functional/flexible frameworks of the above algorithms built from scratch using primarily NumPy. Finally, there is a fully integrated Case Study which deploys several of the custom frameworks (KNN-Classification, Repeated K-Fold Cross Validation) through a full Machine Learning workflow alongside the Iris Flowers dataset to find the optimal KNN model.
GitHub: https://github.com/Amitg4/KNN_ModelValidation
Please use the imports below to run any included code within your own notebook or coding environment.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_iris
from statistics import mean,stdev
from itertools import combinations
import math
%matplotlib inline
KNN Algorithm Overview
K-Nearest Neighbors is a popular pattern recognition algorithm used in Supervised Machine Learning to handle both classification and regression-based tasks. At a high level, this algorithm operates according to an intuitive methodology:
New points target values are predicted according to the target values of the K most similar points stored in the model’s training data.
Traditionally, ‘similar’ is interpreted as some form of a distance calculation. Therefore, another way to interpret the KNN prediction methodology is that predictions are based off the K closest points within the training data, hence the name K-Nearest Neighbors. With the concept of distance introduced, a good initial question to answer is how distance will be computed. While there are several different mathematical metrics that are viewed as a form of computing distance, this study will highlight the 3 following distance metrics: Euclidean, Manhattan, and Chebyshev.
KNN Algorithm Overview — Distance Metrics
Euclidean distance, based in the Pythagorean Theorem, finds the straight line distance between two points in space. In other words, this is equivalent to finding the shortest distance between two points by drawing a single line between Point A and Point B. Manhattan distance, based in taxicab geometry, is the sum of all N distances between Point A and Point B in N dimensional feature space. For example, in 2D space the Manhattan distance between Point A and Point B would be the sum of the vertical and horizontal distance. Chebyshev distance is the maximum distance between Point A and Point B in N dimensional feature space. For example, in 2D space the Chebyshev distance between Point A and Point B would be max(horizontal distance, vertical distance), in other words whichever distance is greater between the two distances.
Consider Point A = (A_1, A_2, … , A_N) and Point B = (B_1, B_2, … , B_N) both exist in N dimensional feature space. The distance between these two points can be described by the following formulas:
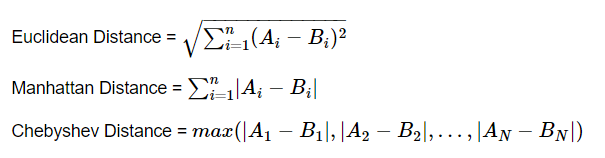
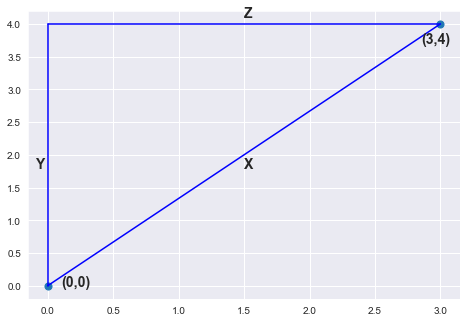
As with most mathematical concepts, distance metrics are often easier to understand with a concrete example to visualize. Consider Point A = (0,0) and Point B = (3,4) in 2D feature space.
sns.set_style('darkgrid')
fig = plt.figure()
axes = fig.add_axes([0,0,1,1])
axes.scatter(x=[0,3],y=[0,4],s = 50)
axes.plot([0,3],[0,4],c='blue')
axes.annotate('X',[1.5,1.8],fontsize = 14,fontweight = 'bold')
axes.plot([0,0],[0,4],c='blue')
axes.annotate('Y',[-0.1,1.8],fontsize = 14,fontweight = 'bold')
axes.plot([0,3],[4,4],c='blue')
axes.annotate('Z',[1.5,4.1],fontsize = 14,fontweight = 'bold')
axes.annotate('(0,0)',[0.1,0.0],fontsize = 14,fontweight = 'bold')
axes.annotate('(3,4)',[2.85,3.7],fontsize = 14,fontweight = 'bold')
axes.grid(lw=1)
plt.show()
#python #machine-learning #siri #k-nearest-neighbors #crossvalidation