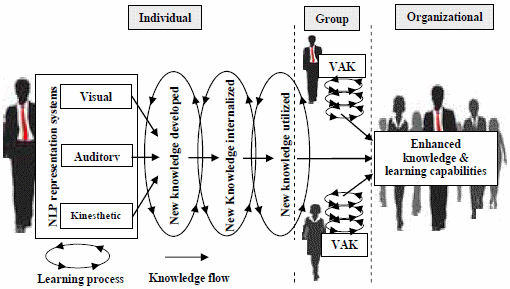
I have explained the bag of words and TFIDF in my first blog. You can find it here**. **Then we discussed some of the issues with TFIDF and learned about word embedding in Part 2, Also how to generate them using Word2Vec. If you want to read about that you can find it here.
I will be showing you some advanced methods and embedding to go for when you are working on an industrial scale project. These include Glove, BERT word embedding, BERT sentence embedding, and Multilingual embedding.
Glove
The Glove was a model proposed by Stanford University in 2014. The goal is very much the same i.e to learn word embeddings and relations between the words. You can read more about Glove here.
Luckily we don’t have train this model from scratch so we can just use the pre-trained embeddings for our use case. All you have to do it is Click **here **and then go to the **Download pre-trained word vectors **section.
You will find these options like Wikipedia, Twitter which is the type of training data they have used to train the model so the notion of the word embedding will be dependent on the corpus. You will also find this 400k vocab, 1.9 M vocab, or 2.2 M vocab, these are the number of words that they have in the vocabulary for that model.
I have downloaded the Wikipedia version with 400K Vocab. You will find these four files which are names something like glove50d, glove100d, or glove300d.

These 50d,100d, or 200d indicates the size of the vector for each word if it is 50 dimensions or 100 dimensions and so on.
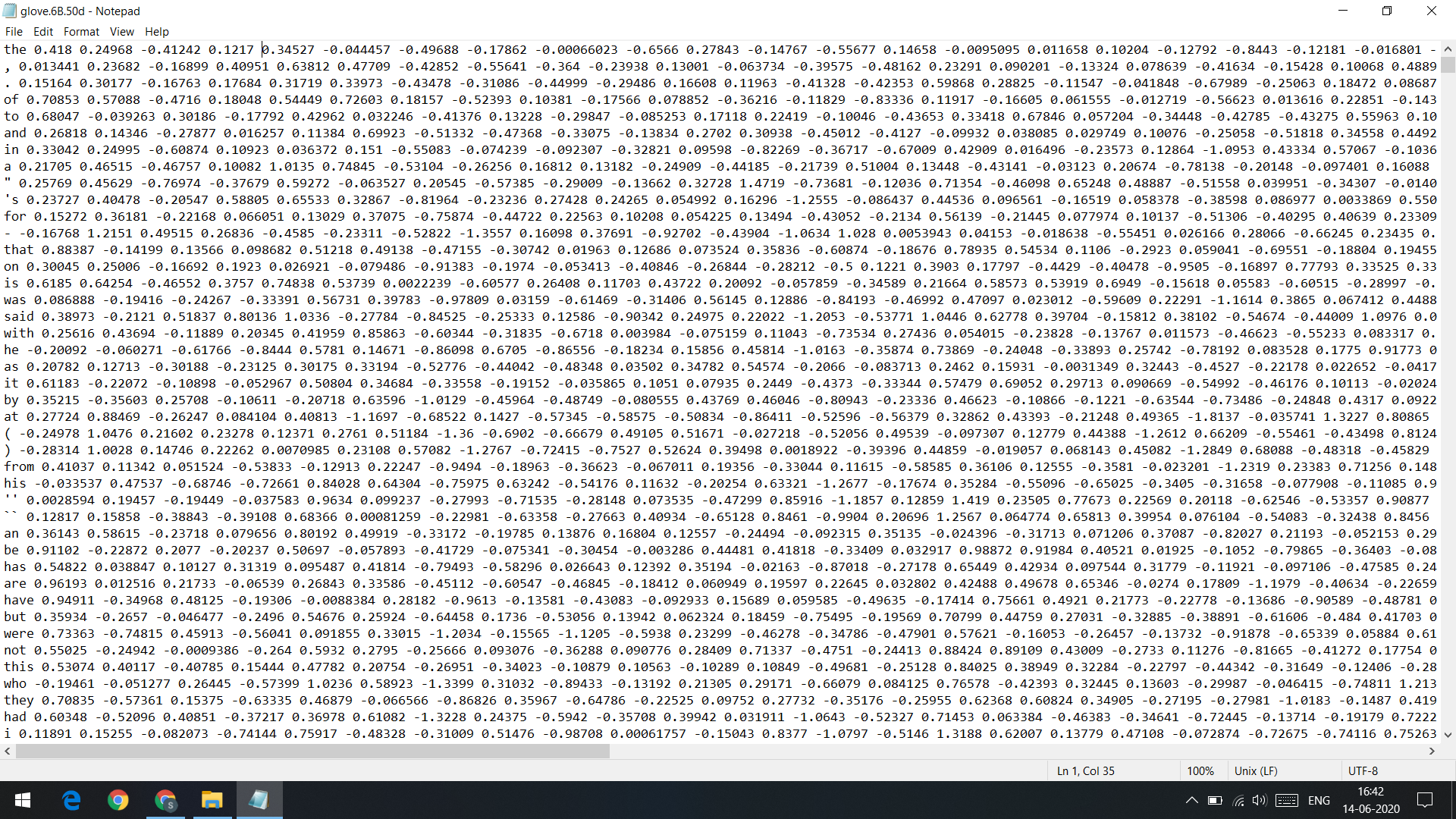
Once you open this file you will find that first value in each row is the word and the rest of the row is the word embedding for that word. Now we just need to read this file and extract out the word embeddings.
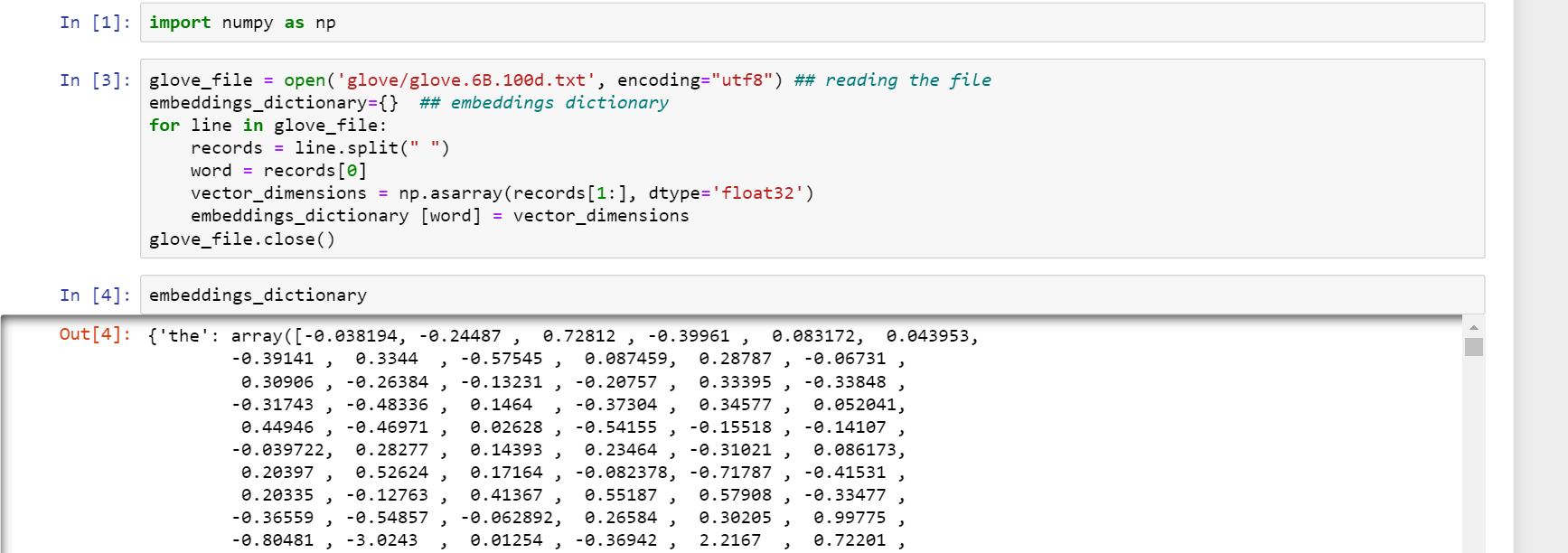
I have used this piece of code to convert the text file into a dictionary of words as keys and its word embeddings as the corresponding value.
You can see we are just looping through each line in the file and setting the first item after splitting as word and remaining as an array. I have used Numpy here as it is efficient and fast.
Now we have the word embeddings for each word in the corpus. You can apply all the techniques we discussed in Part2 and use them as per your need.
There is a variation of size in the word embeddings as 50 dimensions or 100 dimensions. Generally, the idea is if we use word embeddings with a bigger size of the vector we have more information about the word so we should get a boost in the accuracy as the model has more information to learn from.
I was working on a simple sentimental analysis using LSTM neural network. I tried moving from 50 dimensions to 100 dimensions and I got a boost of 5–7 % in the accuracy but as I increased it to 300 dimensions there was not as much of the boost, I only got a boost of 0.03 %. You can try it on your project and see if it helps.
#data-science #nlp #sentence-embedding #word-embeddings #artificial-intelligence