What is Data Normalization?
Data Normalization is a data preprocessing step where we adjust the scales of the features to have a standard scale of measure. In Machine Learning, it is also known as Feature scaling.
Why do we need Data Normalization?
Machine learning algorithms such as Distance-Based algorithms, Gradient Descent Based Algorithms expect the features to be scaled.
Why do these algorithms need the features to be scaled? For answering this, we look at an example. We have data of 35 job holders with two variables years of experience ranging from 1.1 years — 10.5 years and their corresponding salaries ranging from $37k to $122k.
This data was downloaded from this link: https://www.kaggle.com/rsadiq/salary

First 13 rows of the salary data
Distance-Based algorithms, such as SVM, K-Means, and KNN classifies objects by finding similarity between them using distance functions. These algorithms are receptive to the size of the variables. If we don’t scale, the feature with a higher magnitude (Salary), will have more influence than the feature with a lower magnitude (years of experience), and this leads to bias in data, and it also affects the accuracy.
On the other hand, we have Gradient Descent Based Algorithms, which uses the vector-valued function θ. When the scales of the variables are different, θ will descend faster in a lower scale variable as its learning rate will be higher. Therefore, we need to scale the variables to move the gradient with the same learning rate, and this, in turn, will make the convergence faster towards the minima. This can be seen in the diagram below, the left graph is not scaled, and it takes a longer time(as small scale feature has slow learning rate) compared to the scaled data on the right-hand graph.
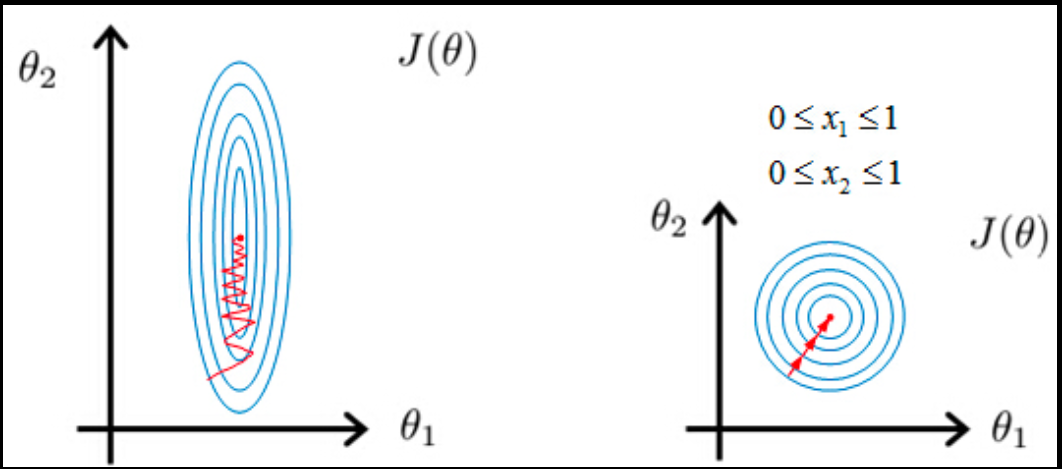
Note: If we are solving for regression parameters in closed-form, we don’t need to apply scaling. But it is always good step to follow. Scaling is essential in regression when we use regularisation(gradient-descent) with it.
We also have Principal Component Analysis(PCA) that requires scaling as it tries to capture maximum variance. If the data is not scaled, this could lead to bias as the feature with a larger scale could influence the smaller-scale features.
Tree-based models follow some rules for classification and regression. Hence, scaling is not required for tree-based models.
Methods of Data Normalization
- Z-score Normalization(Standardization)
- Robust Scalar
- Min-Max Normalization
- Mean Normalization
- Unit Length
Z-score Normalization(Standardization)
Z-score Normalization transforms x to x’ by subtracting each value of features by the sample mean and then dividing by the sample standard deviation. The resulting mean and standard deviation of the standardised values are 0 and 1, respectively.
#standardization #data-normalization-in-r #normalization #data-normalization #feature-scaling #data analysis
