With bunches of hands-on tools, building models on labeled data has already been an easy task for data scientists. However, in the real world, many tasks are not well-formatted supervised learning problems: labeled data may be expensive or even impossible to obtain. An alternative approach is to leverage cheap and low-quality data to achieve supervision, which is the topic of this article: weak supervision
In the following sections, I will go through the concepts of weak supervision. I will also introduce a tool called Snorkel, which is developed by Stanford. Finally, I will show you how HK01 uses Snorkel to capture the trend topics on Facebook, and therefore enhance our recommender engine.
There are several paradigms of algorithm to remedy the situation if a large amount of high-quality, hand-labeled training data is not available. As you can see in the following diagram, if you don’t have enough data, you have to find another source of knowledge to achieve a comparable level of supervision to traditional supervision.

source: http://ai.stanford.edu/blog/weak-supervision/
Choosing one among these paradigms is pretty tricky. It depends on what you have on your hands. Transfer learning is great for tasks with a well-trained model in similar tasks, like fine-tuning ImageNet model with your own categories; while you may have some presumptions on the topological structure, such as the shape of clusters, you may prefer semi-supervised learning.
So, what kind of situation is the best suit for weak supervision?
You may have some ideas after reading the definition of weak supervision. Yes, if you have plenty of domain experts but lack of data, weak supervision is your pick.
The reason behind is revealed in the definition: weak supervision enables learning from low-quality and noisy labels. In other words, you can still find patterns, just like what supervised learning do, unless you should supplement multiple noisy labels for each training sample so that the model can generalize knowledge from them.
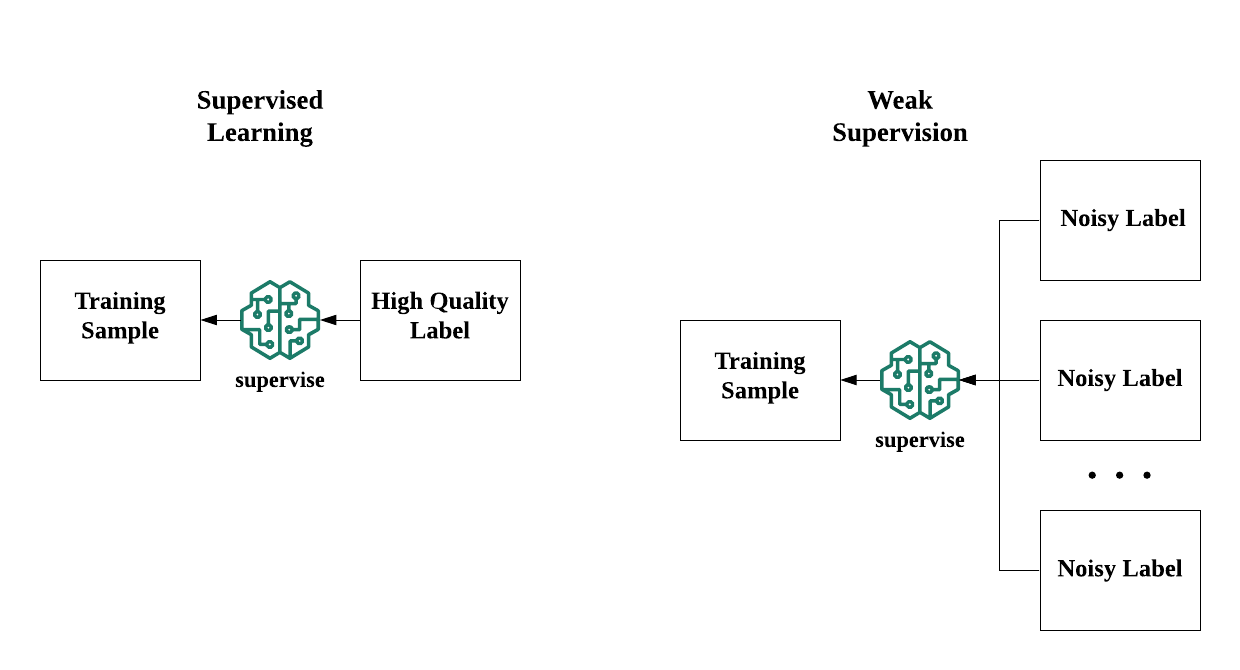
weak supervision enables supervision by multiple noisy labels
The rationale of weak supervision relies on the fact that noisy data is usually much easier and cheaper to obtain than high-quality data. Imagine you are working for an insurance company and your boss asks for a recommender engine of a whole-new product line which, of course, you don’t have data. With sales experts, we can set up some rules which are “mostly correct” like the new product is more attractive to the elderly. These rules are not perfectly correct; but, they are good enough to provide your models collective intelligence. And, most importantly, these rules are easier to obtain than perfectly hand-labeled data.
So, the next question is: **how can we inject these rules into our ML models? **The answer is Snorkel.
Snorkel is a system developed by Stanford which allows you to program the rules into ML models. The key idea of Snorkel is to build the generative model which represents the causal relationship between the true label and the noisy labels.
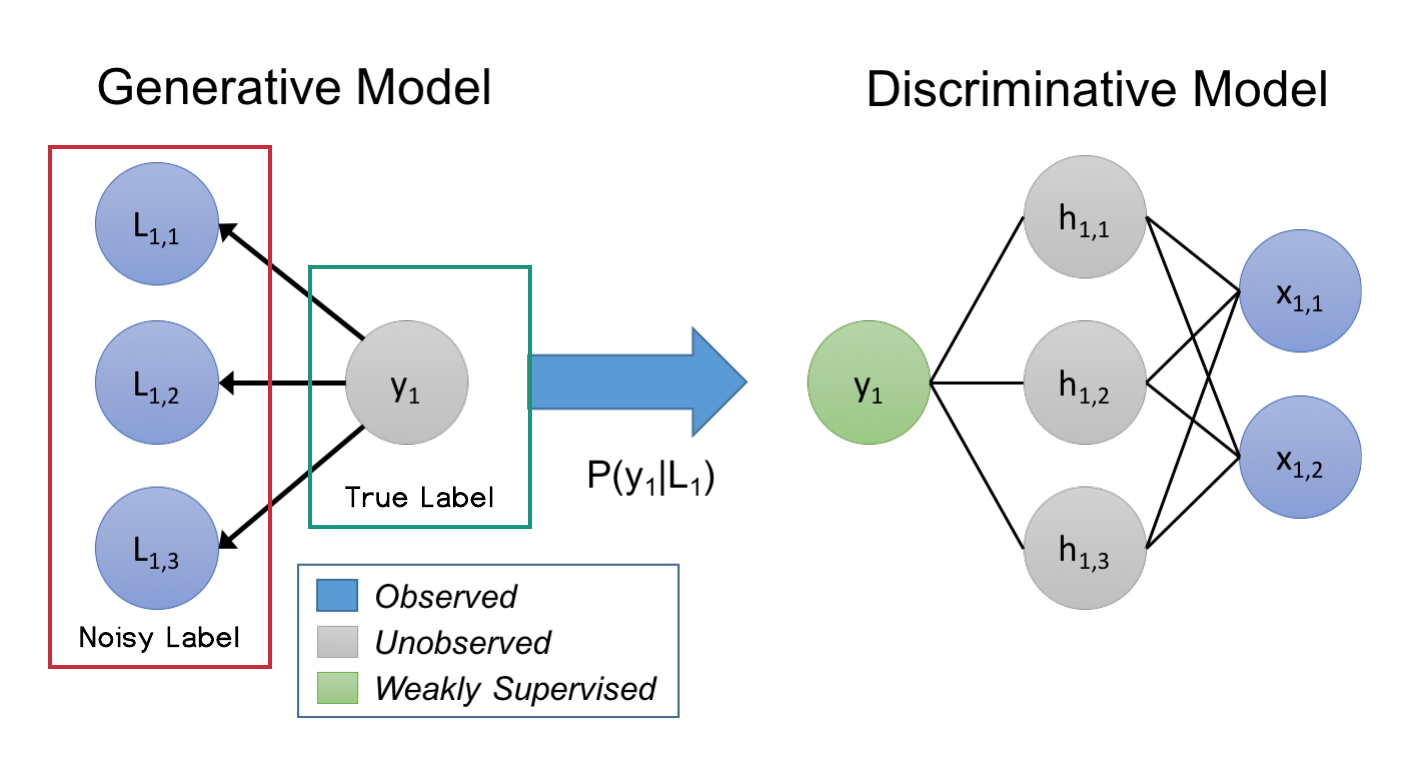
The left-hand side of the above diagram is the probabilistic model representing the generative process from the true label to the noisy labels. Although the true label is unobservable, we can still learn the accuracies and correlations by the agreements and disagreements from different noisy labels. Hence, we can estimate the P(L|y) of each noisy label, which is essentially an indicator of quality. By aggregating the noisy labels, we get the estimated true label and use it to train our model.
In Snorkel, noisy labels are programmed as labeling functions. A label function is basically a python function which hard-codes a rule to determine the label. For example, if you’re writing a program to determine which an email is spam, the program should be something like:
from snorkel.labeling import labeling_function
SPAM = 1
NORMAL = 0
ABSTAIN = -1
@labeling_function()
def contain_hyperlink(x):
if 'http' in x:
return SPAM
else:
return NORMAL
@labeling_function()
def contain_foul_language(x):
for each in x:
if each in foul_language:
return SPAM
else:
return NORMAL
In this toy example, you can see the basic elements of Snorkel.
- define the labels. In this example, the labels are SPAM, NORMAL & ABSTAIN. ABSTAIN is the label used when you cannot determine the label.
- define labeling functions. Add a decorator
@labeling_function()to declare.
#machine-learning #deep-learning #transfer-learning #semi-supervised-learning #weak-supervision #deep learning
