Principle of BIRCH clustering algorithm
The BIRCH algorithm is more suitable for the case where the amount of data is large and the number of categories K is relatively large. It runs very fast, and it only needs a single pass to scan the data set for clustering. Of course, some skills are needed. Below we will summarize the BIRCH algorithm.
BIRCH overview
BIRCH stands for Balanced Iterative Reducing and Clustering Using Hierarchies, which uses hierarchical methods to cluster and reduce data.
- BIRCH only needs to scan the data set in a single pass to perform clustering.
How does it work?
The BIRCH algorithm uses a tree structure to create a cluster. It is generally called the Clustering Feature Tree (CF Tree). Each node of this tree is composed of several Clustering features (CF).
Clustering Feature tree structure is similar to the balanced B+ tree
From the figure below, we can see what the clustering feature tree looks like.
Each node including leaf nodes has several CFs, and the CFs of internal nodes have pointers to child nodes, and all leaf nodes are linked by a doubly linked list.
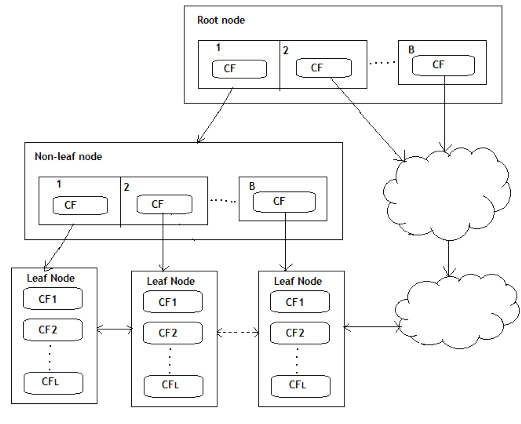
From [Research Paper]
Clustering feature (CF) and Cluster Feature Tree (CF Tree)
In the clustering feature tree, a clustering feature (CF) is defined as follows:
Each CF is a triplet, which can be represented by (N, LS, SS).
- Where N represents the number of sample points in the CF, which is easy to understand
- LS represents the vector sum of the feature dimensions of the sample points in the CF
- SS represents the square of the feature dimensions of the sample points in the CF.
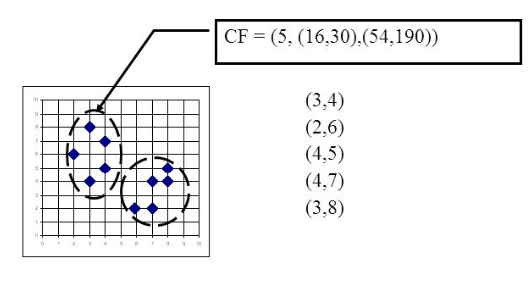
For example, as shown in the following figure, in a CF of a node in the CF Tree, there are the following 5 samples (3,4), (2,6), (4,5), (4,7), ( 3,8). Then it corresponds to
CF has a very good property. It satisfies the linear relationship, that is:
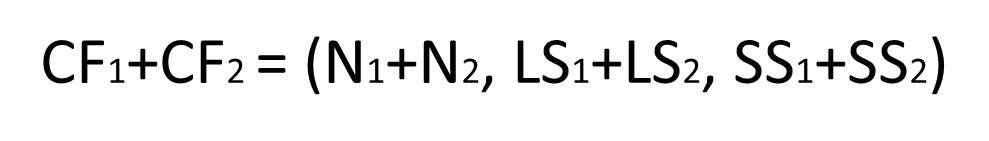
This property is also well understood by definition. If you put this property on the CF Tree, that is to say, in the CF Tree, for each CF node in the parent node, its (N, LS, SS) triplet value is equal to the CF node pointed to The sum of the triples of all child nodes.
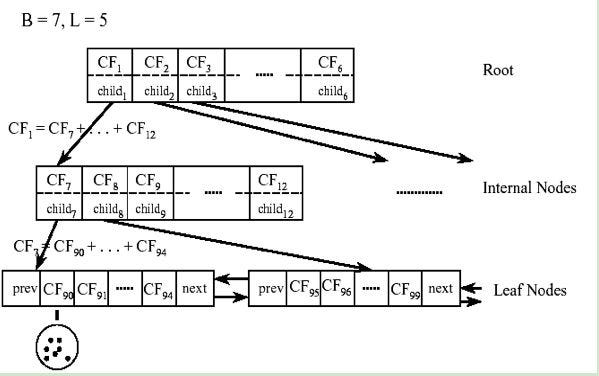
From notes by By T, Zhang, R. Ramakrishnan
As can be seen from the above figure, the value of the triplet of CF1 of the root node can be obtained by adding the values of the 6 child nodes (CF7-CF12) that it points to. In this way, we can be very efficient when updating the CF Tree.
For CF Tree, we generally have several important parameters,
- The first parameter is the maximum CF number B of each internal node,
- The second parameter is the maximum CF number L of each leaf node,
- The third parameter is for the sample points in a CF in the leaf node. It is the maximum sample radius threshold T of each CF in the leaf node. That is to say, all sample points in this CF must be in the radius In a hyper-sphere less than T.
For the CF Tree in the above figure, B = 7 and L = 5 are defined, which means that the internal node has a maximum of 7 CFs, and the leaf node has a maximum of 5 CFs.
#clustering-algorithm #machine-learning #data-science #data-mining #algorithms
