K-means clustering is a widely-used, and relatively simple, unsupervised machine learning model. As the name implies, this algorithm works best when answering questions in regards to how similar, or dissimilar, data objects are in our dataset. If good clustering exists in our data, then it will usually be efficiently found. But if we have poorly clustered data or data with high dimensionality, the model can suffer and produce unreliable predictions. Regardless, clustering is a very useful tool in terms of data exploration, and as a budding data scientist, an integral stepping stone in my journey. With a basic run-down out of the way, let’s break down a K-means clustering algorithm from scratch and see what goes on behind the scenes so-to-speak, to gain a better understanding of the algorithm in the process.
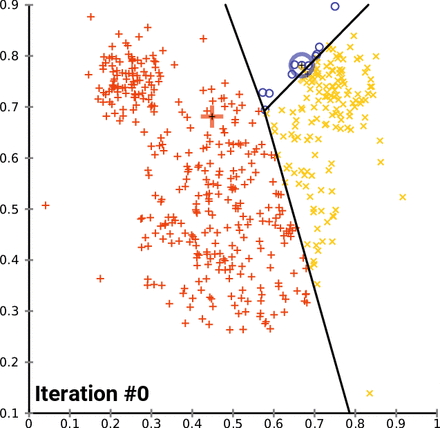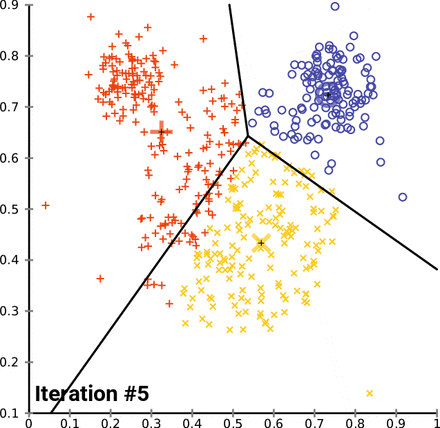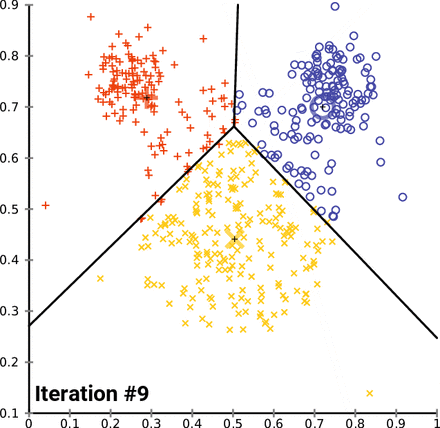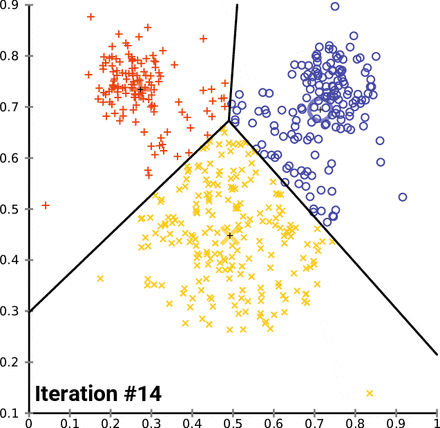
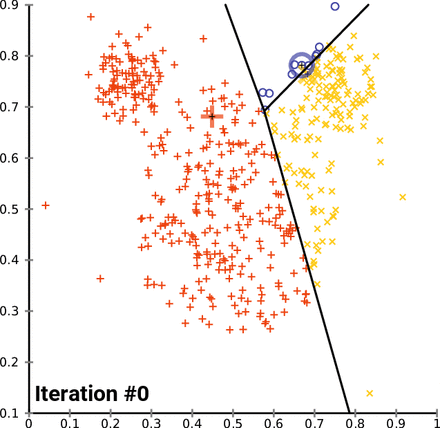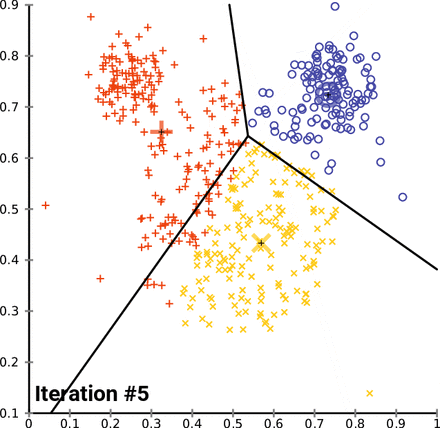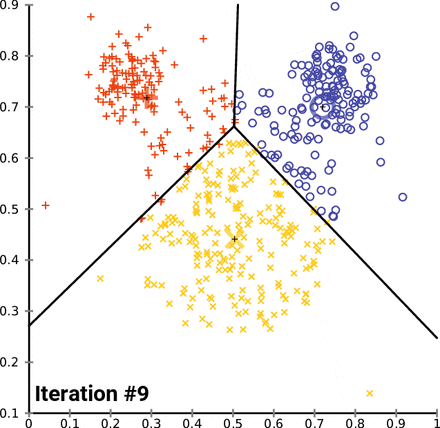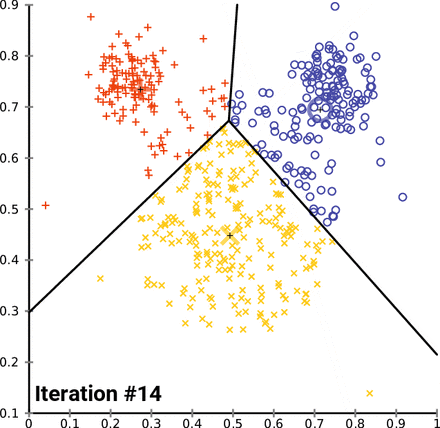
How K-Means clusters over time/iterations
The K-Means Clustering Process:
Looking at the image above, you may be wondering, “What are those three big markers moving around altering the data with every iteration?” Well, those markers are known as centroids and they’re imperative to K-means clustering, a centroid-based clustering algorithm. Think of centroids as imaginary team captains, that gravitate toward the center of clustered data and assign data closest to them to their team. “But how does this work?”, you might ask. Lets go over the clustering process and then break it down piece by piece.
- ) Select n_clusters, random data points, that act as initial centroids. (One point for each cluster)
- ) Find the clusters of data points surrounding those centroid(s).
- ) Calculate new centroid(s) for the clusters.
- ) Repeat steps 2 and 3 until the model can no longer detect a significant change in it’s constantly updated centroid(s).
Setting up the algorithm:
Before we can get into how the algorithm operates, we must first initialize it.
#python #k-means-clustering