A 16 minute introduction to performing parallel operations in Python
`Photo by Michael Dziedzic on Unsplash
Introduction
Python has a very powerful data analysis stack in the form of Pandas, Numpy, Scipy etc., but none of these libraries offer parallelism. Dask injects the much-needed parallel processing that has always been holding these libraries back from server level deployment. Dask provides parallelism for analytics, enabling performance at scale for existing python structures like, Numpy arrays, Pandas dataframes and machine learning tools from SciKit-Learn. Apart from parallelism in arrays and dataframes, Dask packs in itself a variety of advantages.

Firstly, Dask was initially designed to parallelise just Numpy and Pandas but now has come to be used for arbitrary computations as well. Secondly, most of the syntax for creation of arrays and dataframes is remarkably similar to how it is done in Numpy and Pandas. Dask uses existing Python APIs, making it easy to move from Numpy, Pandas, Scikit-learn to their Dask equivalents.
This eliminates the need to rewrite your code or retrain your models, saving time and money for engineering teams. Finally, Dask can parallelise operations equally easily on a computer as on a server. It automatically figures out the cores in a machine and intelligently distributes workload.Let’s see how to set it up and get working with it.
Installs
Dask can be installed using one of the following
- Conda
- pip
- Source
Conda
Anaconda is a package management tool in python. It comes loaded with dask. It can be installed/updated using the following
conda install dask
This command will install all data analysis libraries along with Dask’s dependencies, including Pandas and NumPy.
Pip
The ever-popular command-line installation tool of python can also be used to install Dask and its dependencies like NumPy and Pandas etc.
python -m pip install “dask[complete]” # Install everything
Just the Dask library can also be installed instead of the complete collection but that will leave out important modules like dask.array, dask.dataframe, dask.delayed, or dask.distributed. So, it makes sense to install the complete package.
Source
To install Dask from its source, we use github to clone the source repo and then run the install command
git clone https://github.com/dask/dask.git
cd dask
python -m pip install .
Parallelising Custom Code
Once installed we are good to go. We can start playing with the various structures that Dask offers in parallel to Numpy and Pandas. Before that, however, let’s take a look at how Dask parallelises custom Python code like function calls and loops.
Functions
Let’s define 3 functions — square, double and mul. We will add a delay into these functions and compare their running time with and without Dask
from time import sleep
def double(x):
sleep(1)
return x * 2
def square(x):
sleep(1)
return x ** 2
def mul(x,y):
sleep(1)
return x*y
%%time
# Note the Wall Time
# It is 3 secs because each function runs sequentially
num1 = double(2)
num2 = square(3)
prod = mul(x, y)

Timing Results Without Dask
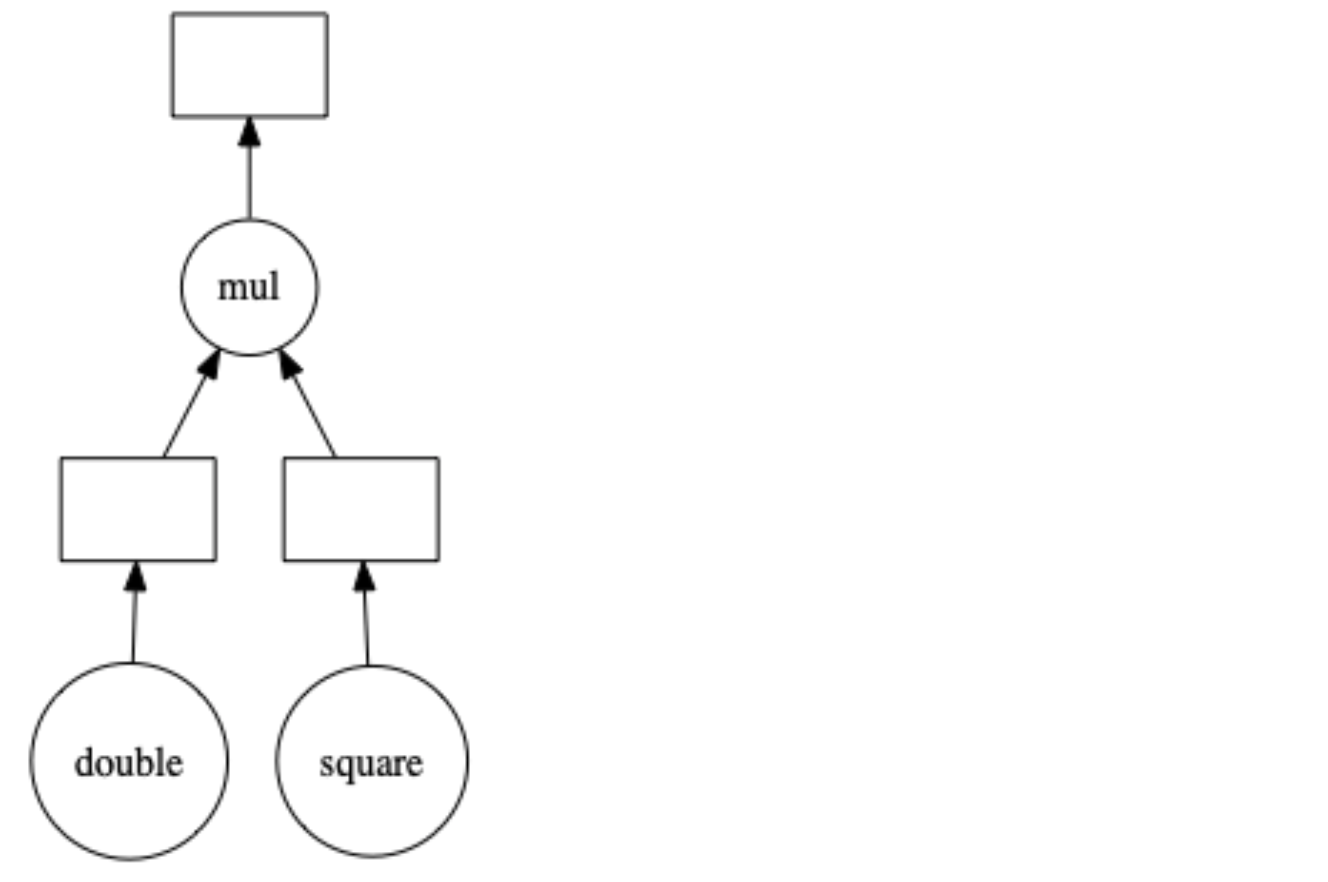
Now let’s try parallelising this with Dask. The method we use for this is called delayed. When functions are independent, they can be run in parallel using **delayed function. **The Dask “delayed” function makes your functions operate lazily. Instead of executing the function immediately, it will postpone the execution, placing the function and its arguments into a task graph. Let’s see how that looks like.
from dask import delayed
%%time
# This runs instantly,
# No computation happens as of now, all it does is build a graph
num1 = delayed(double)(2)
num2 = delayed(square)(3)
prod = delayed(mul)(x, y)

Dask builds a task graph. No actual computation has happened.
Look at how this step takes almost no time because at this point, only a task graph is built. The actual computation will happen next. Let’s also calculate the time for it.
%%time
# Actual computation happens here
# 1 Sec to compute num1 and num2\. 1 Sec to compute prod
prod.compute()

Actual Computation with Dask
Look at the 1 second time gain we get because num1 and num2 get calculated in parallel. To execute any function in parallel just wrap it within **delayed() **function and that function will be evaluated lazily. If you now check the type of the variable **prod, **it will be Dask.delayed type. For such types we can see the task graph by calling the method visualize()
- Actual Computation happens only when we execute compute()
- **Delayed() **method causes lazy execution
- **Visualize() **method shows the task graph
# How the task graph for prod is made
prod.visualize()
#web-development #python #programming #technology #coding