So, before we starting the model implementation we have to know some concept of word embedding and LSTM. Let’s begin with them first.
Word Embedding
Word Embedding is the technique of representation for text where words that have the same meaning have a similar representation. It is this approach to representing words and documents that may be considered one of the key breakthroughs of deep learning on challenging natural language processing problems.
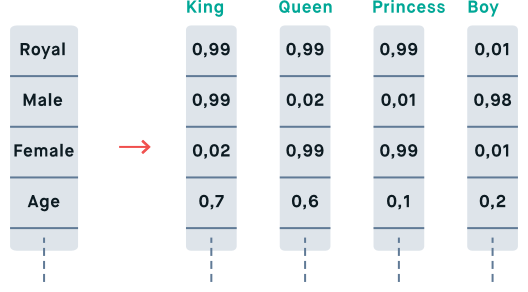
For Deep detail, you can refer to this article
Word Embeddings for NLP
Understanding word embeddings and their usage in Deep NLP
LSTM(Long Short Time Memory)
LSTM is a type of Recurrent neural network. It was designed by Hochreiter & Schmidhuber.
It solved the problem of long-term dependencies of RNN — where the RNN cannot predict the word stored in the long term memory but can give more accurate predictions from the recent information.
While the gap length increases, RNN does not give efficient performance, but LSTM can retain the information for a long period of time. It is used for processing, predicting, and classifying on the basis of time-series data.
Structure of LSTM
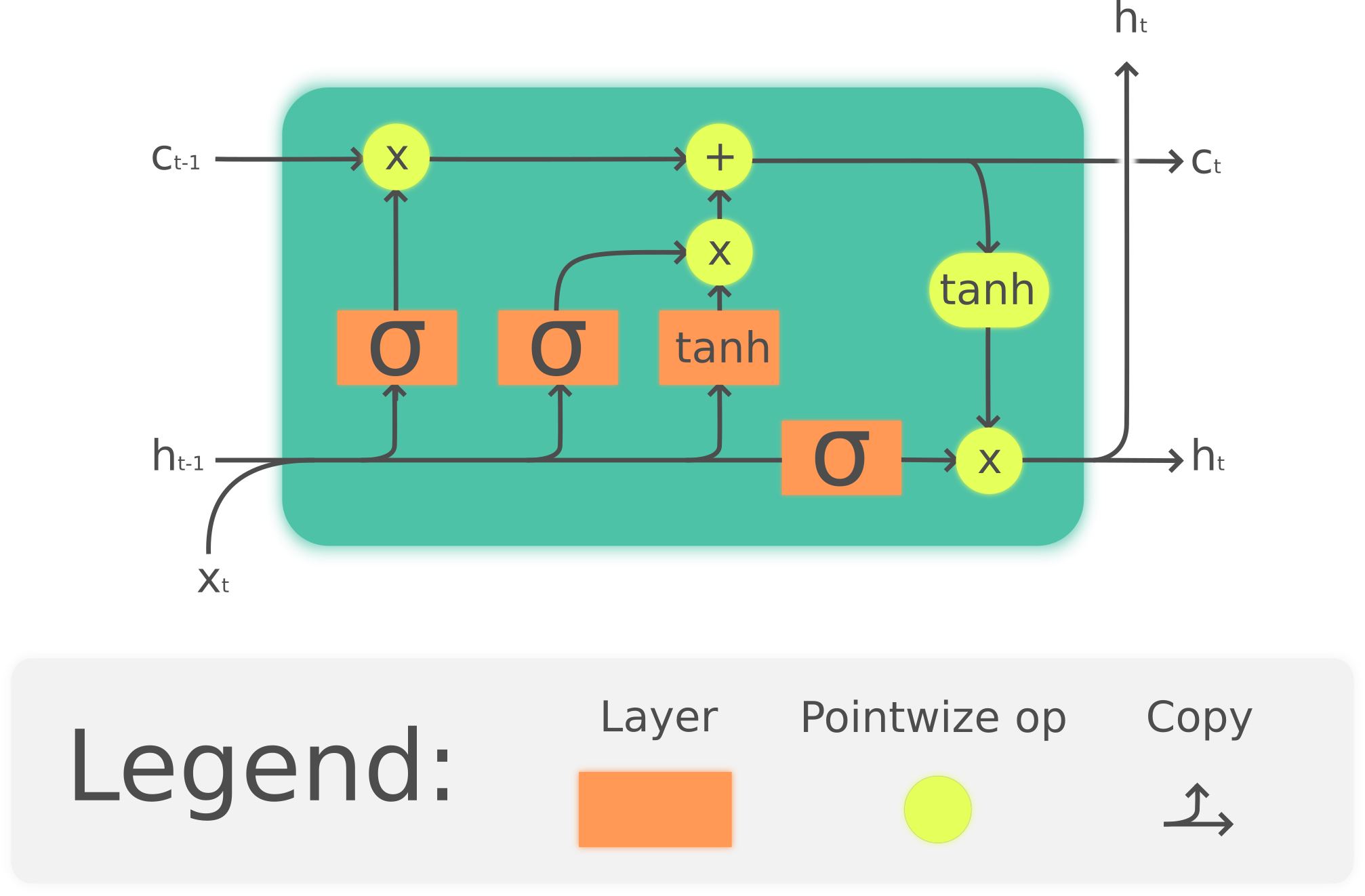
Structure of LSTM
Implementation
Importing and Loading the datasets
import pandas as pd
df=pd.read_csv('train.csv')
df.head()
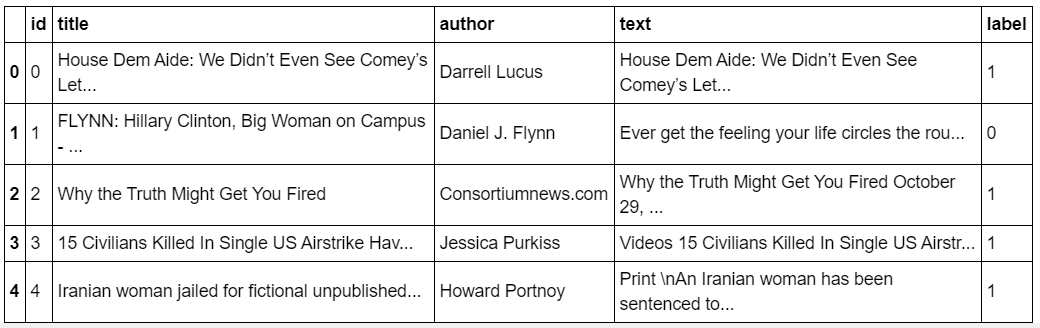
Image by author
This dataset has 5 features so here we can consider only 4 feature because
id column is not highly co-related to the dependent variables.
Dataset is available on [Kaggle]
#machine-learning #data-science #deep-learning #news #fake-news #data analysis