In previous posts, I tried to predict if a bank customer is likely to leave, OR if an app user is likely to churn or subscribe. Here I will share recent work in the human resource domain to bring some predictive power to any firm struggling to retain their employees.
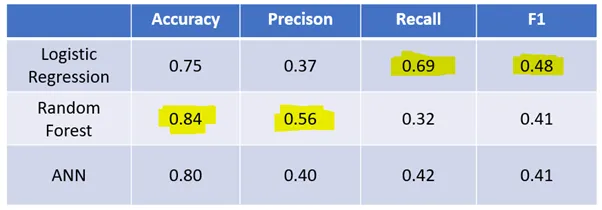
In this second post, I aim to evaluate and contrast the performances of a handful of different models. As always, it is split into:
1. Data Engineering
2. Data Processing
3. Model Creation & Evaluation
4. Takeaways
1. Data Engineering
_Having completed a brief data exploration in the first _post, let’s proceed with feature engineering and data encoding. Feature engineering involves creating new features and relationships from current features.
To start off, let’s segregate the categorical variables from numerical ones. We can use the **datatype method **to find categorical variables, as their **dtype **would be ‘object’. You may notice data types are already shown when using employee_df.info().
#logistic-regression #random-forest #machine-learning #artificial-neural-network #binary-classification