Last year I was working on a project that dealt with Twitter data. We had around a billion tweets in our database. I needed to clean our data so that we can run some machine learning models on it.
Here is a snapshot of the Dataset:

Weird Unicode characters (emojis), random missing values with changing identifiers, etc. I still have nightmares about that project.
But, that’s how real-world datasets are. You get missing values, random characters, wrong data types, etc. According to some statistics, data scientists end up spending 80% of their time organizing and cleaning data.
A common occurrence in a data-set is missing values. This can happen due to multiple reasons like unrecorded observations or data corruption.
In this tutorial, we will walk through many different ways of handling missing values in Python using the Pandas library.
Pandas library provides a variety of functions for marking these corrupt values. We will study how we can remove or impute these values.
Setup
All the examples in this tutorial were tested on a Jupyter notebook running Python 3.7. We will be using NumPy and Pandas in this tutorial.
_There is an accompanying Jupyter notebook for this tutorial here
I would highly recommend setting up a virtual environment with all the required libraries for testing. Here is how you can do it.
$ virtualenv missing_data
$ source ./missing_data/bin/activate
$ pip3 install pandas numpy
The Employee Dataset
We will be working with a small Employee Dataset for this tutorial.
_Download the dataset in CSV format from my Github repo and store it in your current working directory: employees.csv
Let us import this dataset into Python and take a look at it.
# Importing libraries
import pandas as pd
import numpy as np
# Read csv file into a pandas dataframe
df = pd.read_csv("employees.csv")
# Prints out the first few rows
print(df.head())
Output:
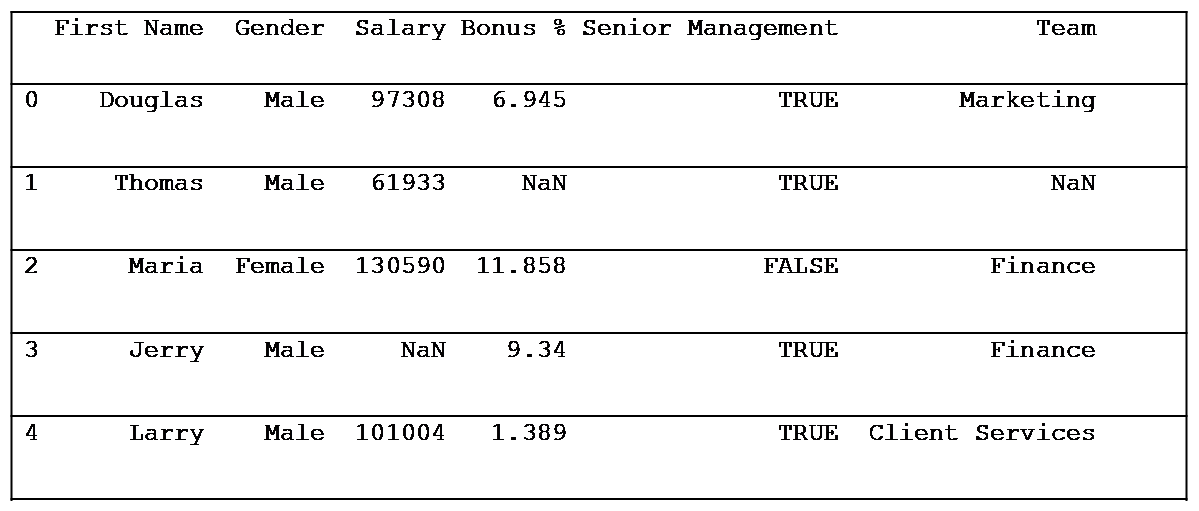
We read the CSV file into a Pandas DataFrame. The .head() method returns the first five rows of the DataFrame.
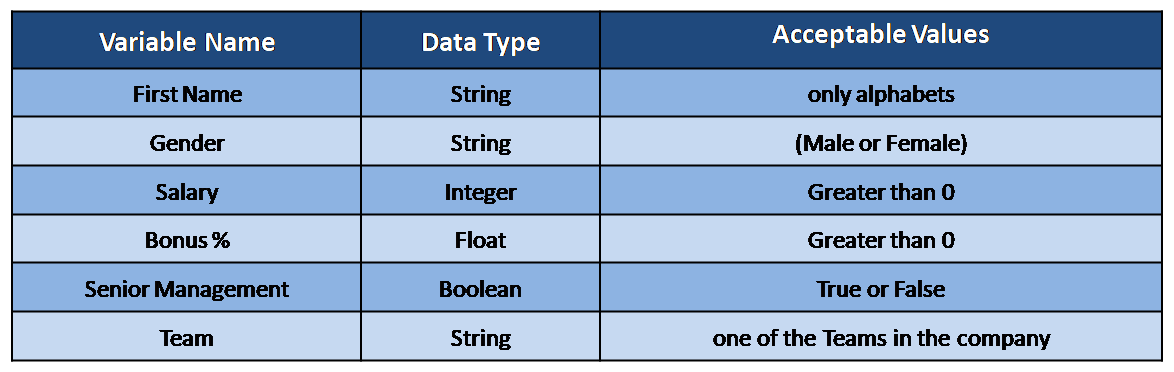
The dataset has 1000 observations with six variables as given below:
#python-programming #programming #data-science #data #machine-learning #python