Introduction
COCO (official website) dataset, meaning “Common Objects In Context”, is a set of challenging, high quality datasets for computer vision, mostly state-of-the-art neural networks. This name is also used to name a format used by those datasets.
Quoting COCO creators:
COCO is a large-scale object detection, segmentation, and captioning dataset. COCO has several features:
- Object segmentation
- Recognition in context
- Superpixel stuff segmentation
- 330K images (>200K labeled)
- 1.5 million object instances
- 80 object categories
Format of this dataset is automatically understood by advanced neural network libraries, e. g. Facebook’s Detectron2 (link). There are even tools built specifically to work with datasets in COCO format, e. g. COCO-annotator and COCOapi. Understanding how this dataset is represented will help with using and modifying the existing datasets and also with creating the custom ones. Specifically, we are interested in annotationsfiles, since complete dataset consists of images directory and annotation file, providing metadata used by machine learning algorithms.
What can you do with COCO?
There are actually multiple COCO datasets, each one made for a specific machine learning task, with additional data. The 3 most popular tasks are:
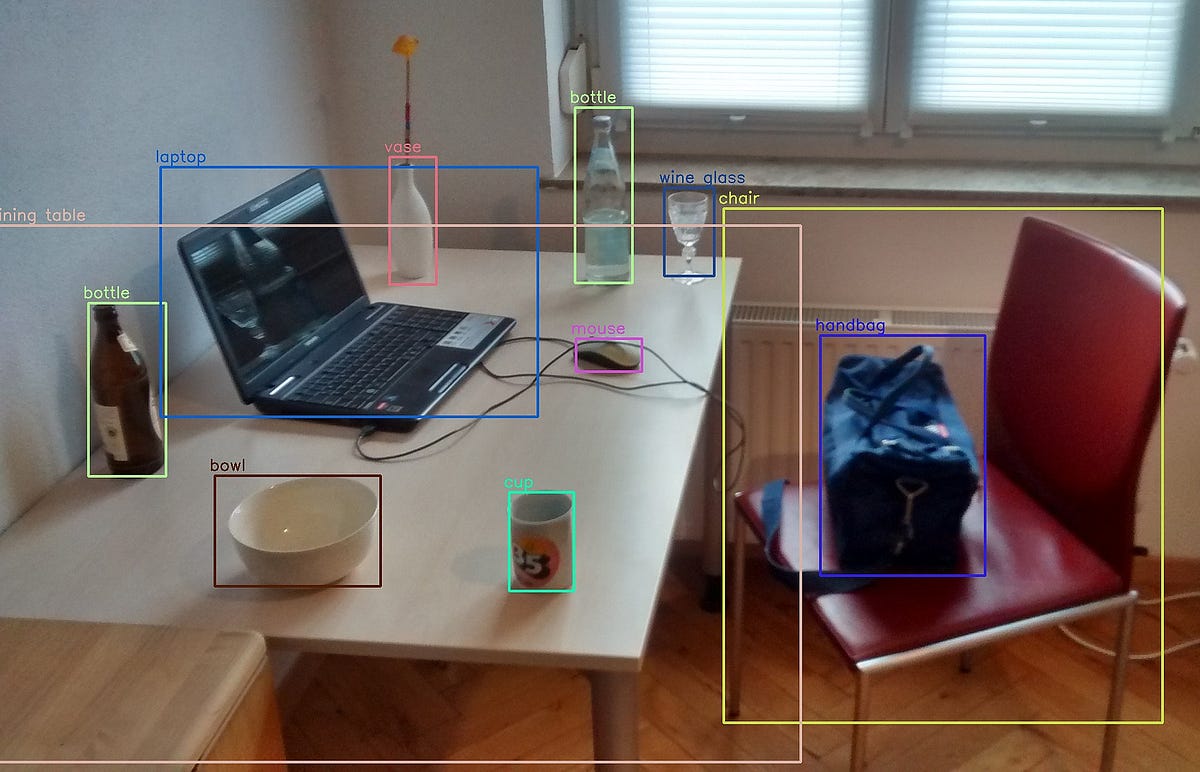
- object detection — model should get bounding boxes for objects, i. e. return list of object classes and coordinates of rectangles around them; objects (also called “things”) are discrete, separate objects, often with parts, like humans and cars; the official dataset for this task also contains additional data for object segmentation (see below)
#machine-learning #ai #coco #dataset #computer-vision