Introduction
**_Word embeddings _**have become one of the most used tools and main drivers of the amazing achievements of Artificial Intelligence tasks that require processing natural languages like speech or texts.
In this post, we will unveil the magic behind them, see what they are, why they have become a standard in the **Natural Language Processing **(NLP hereinafter) world, how they are built, and explore some of the most used word embedding algorithms.
Everything will be explained in a simple and intuitive manner, avoiding complex maths and trying to make the content of the post as accessible as possible.
It will be broken down in the following subsections:
- What are word embeddings?
- Why should we use word embeddings?
- How are word embeddings built?
- What are the most popular word embeddings?
Once you are ready, let’s start by seeing what word embeddings are.
1) What are word embeddings?
Computers break everything down to numbers. Bits (zeros and ones) more specifically. What happens when a software inside a computer (like a Machine Learning algorithm for example) has to operate or process a word? Simple, this word needs to be given to the computer as the only thing it can understand: as numbers.
In NLP, the most simple way to do this is by creating a vocabulary with a huge amount of words (100.000 words let’s say), and assigning a number to each word in the vocabulary.
The first word in our vocabulary (‘apple’ maybe) will be number 0. The second word (‘banana’) will be number 1, and so on up to number 99.998, the previous to last word (‘king’) and 999.999 being assigned to the last word (‘queen’).
Then we represent every word as a vector of length 100.000, where every single item is a zero except one of them, corresponding to the index of the number that the word is associated with.
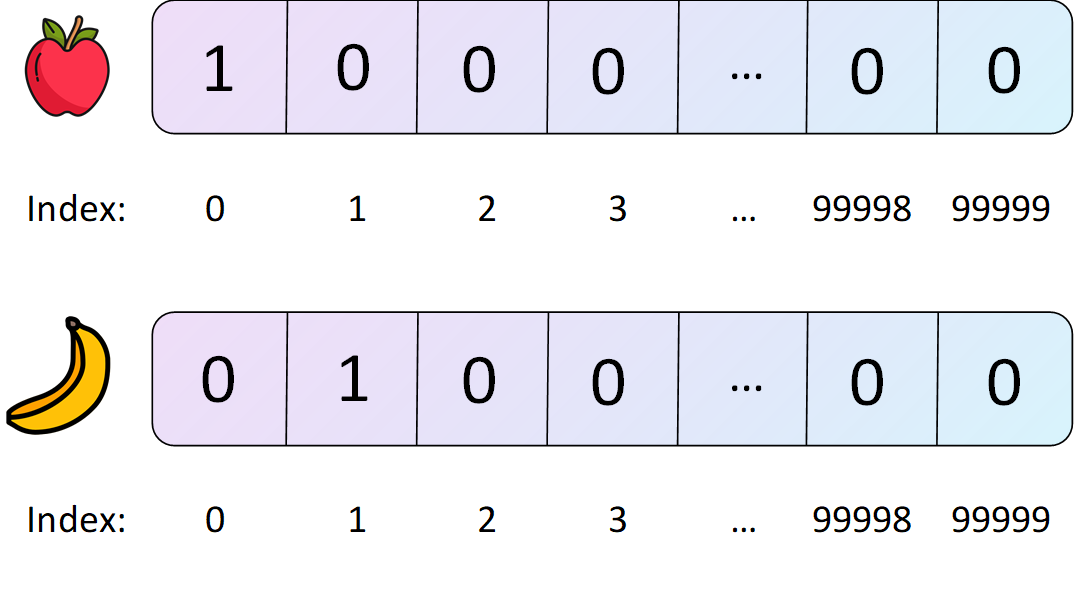
Vector representations of some of the examples from the previous paragraphs.
This is called one-hot encoding for words.
The** one-hot encoding have various different issues** related with efficiency and context, that we will see in just a moment.
Word embeddings are just another form representing words through vectors, that successfully solve many of the issues derived from using a one-hot encoding by somehow abstracting the context or high-level meaning of each word.
The main takeaway here is that word embeddings are vectors that represent words, so that similar meaning words have similar vectors.
#startup #technology #data-science #data analysis
