Transformers have become the defacto standard for any NLP tasks nowadays. Not only that, but they are now also being used in Computer Vision and to generate music. I am sure you would all have heard about the GPT3 Transformer and its applications thereof. But all these things aside, they are still hard to understand as ever.
It has taken me multiple readings through the Google research paper that first introduced transformers along with just so many blog posts to really understand how a transformer works.
So, I thought of putting the whole idea down in as simple words as possible along with some very basic Math and some puns as I am a proponent of having some fun while learning. I will try to keep both the jargon and the technicality to a minimum, yet it is such a topic that I could only do so much. And my goal is to make the reader understand even the goriest details of Transformer by the end of this post.
So, here goes — This post will be a highly conversational one and it is about “Decoding The Transformer”.
Q: So, Why should I even understand Transformer?
In the past, the LSTM and GRU architecture(as explained here in my past post on NLP) along with attention mechanism used to be the State of the Art Approach for Language modeling problems (put very simply, predict the next word) and Translation systems. But, the main problem with these architectures is that they are recurrent in nature, and the runtime increases as the sequence length increases. That is, these architectures take a sentence and process each word in a sequential way, and hence with the increase in sentence length the whole runtime increases.
Transformer, a model architecture first explained in the paper Attention is all you need, lets go of this recurrence and instead relies entirely on an attention mechanism to draw global dependencies between input and output. And that makes it FAST.
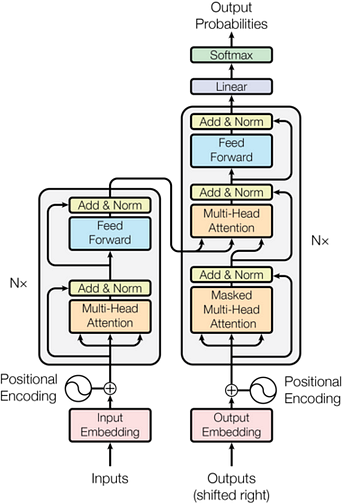
This is the picture of the full transformer as taken from the paper. And, it surely is intimidating. So, I will aim to demystify it in this post by going through each individual piece. So read ahead.
The Big Picture
Q: That sounds interesting. So, what does a transformer do exactly?
Essentially, a transformer can perform almost any NLP task. It can be used for language modeling, Translation, or Classification as required, and it does it fast by removing the sequential nature of the problem. So, the transformer in a machine translation application would convert one language to another, or for a classification problem will provide the class probability using an appropriate output layer.
It all will depend on the final outputs layer for the network but, the Transformer basic structure will remain quite the same for any task. For this particular post, I will be continuing with the machine translation example.
So from a very high place, this is how the transformer looks for a translation task. It takes as input an English sentence and returns a German sentence.

#data science #computer vision #nlp #transformers
