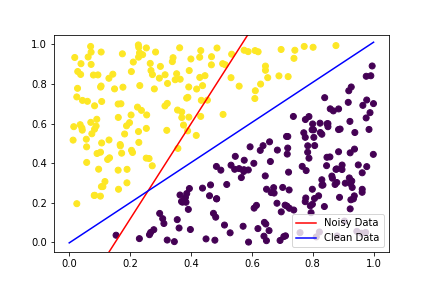
The performance of any classifier, or for that matter any machine learning task, depends crucially on the quality of the available data. Data quality in turn depends on several factors- for example accuracy of measurements (i.e. noise), presence of important information, absence of redundant information, how much collected samples actually represent the population, etc. In this article we will focus on noise, in particular label noise- the scenario when a sample can have exactly one label (or class), and a _subset _of samples in the dataset are mislabeled. We will look at what happens to classification performance when there’s label noise, how exactly it hampers the learning process of classifiers, and what we can do about it.
We’ll restrict ourselves to “matrix-form” datasets in this post. While many of the points raised here will no doubt apply to deep learning, there are enough practical differences for it to require a separate post. Python code for all the experiments and figures can be found in this link.
#data #machine-learning #data-science #classification