Originally posted on Altostra
The Scalable Webhook
Though very useful in the cases of webhooks, the “Scalable Webhook” pattern is useful whenever you need to decouple live requests from long background work (think of updating a DB, querying external services, and so forth).
Many of our customers at Altostra have been using some form or another of this popular pattern, referencing Jeremy’s post on serverless patterns. In this post we’ll see how you can easily implement it using Altostra.
What are we trying to solve?
Let’s say you’re a developer working in a marketing company with a loyal clientele of a few hundred thousand customers. You’re keeping your happily engaged customers up-to-date with customized emails, and whenever an email is opened, clicked, or marked as spam, you get a call to your API address (the webhook) with the id of the email and the type of the event (“Clicked”, “Opened”, “Spam”).
You need to:
1. Verify that the call is authentic and not fake (quite fast)
2. Mark the specific products in the email as “viewed” by the customer using an internal RDS DB
3. Keep the email statistics for further processing by the marketing team
The basic solution is simple: Connect an API Gateway route to a Lambda function, validate the message, mark the email as read in your RDS DB, and save it to a high volume DynamoDb table. This should work, shouldn’t it?
You probably already figured out that this sunny day scenario is not going to last long — actually, it will probably fail in the first high-traffic peak.
First, there’s the too-easy-to-forget AWS Concurrent executions limit — this means that, by default, you can have at most ~1,000 lambda instances running at the same time in the same region (you can request an increase to that limit, but there’s always a limit). This means that if you’ll have a sudden peak in requests (e.g, everybody opened their emails first thing Monday morning) — you’re busted, and you’re losing data.
The second point is your DB. If you’re working with a good old RDS DB, you know that writing to it takes a while — which means that your Lambda takes longer to run, which means that even if the incoming requests rate is not that high, you’re still likely to reach the concurrent execution limit — and in the process, load the DB so much that other, unrelated services might be also affected.
The third point is your other services — if your Lambda needs to do anything that requires any external service, you’ll need to make sure that this other service is capable of coping with your incoming request rates — and sometimes that’s just ain’t possible, in cases where you’re using services which limit query/minute rates.
So, what we need is a way to save all the data that arrives, and process it in our desired rate. That’s right, we need a Queue. But not only do we need a queue, we also need to limit the concurrency level of our executing Lambda so we won’t kill our DB or other services (we’ll just be pushing our problem downstream)
Solution Outline
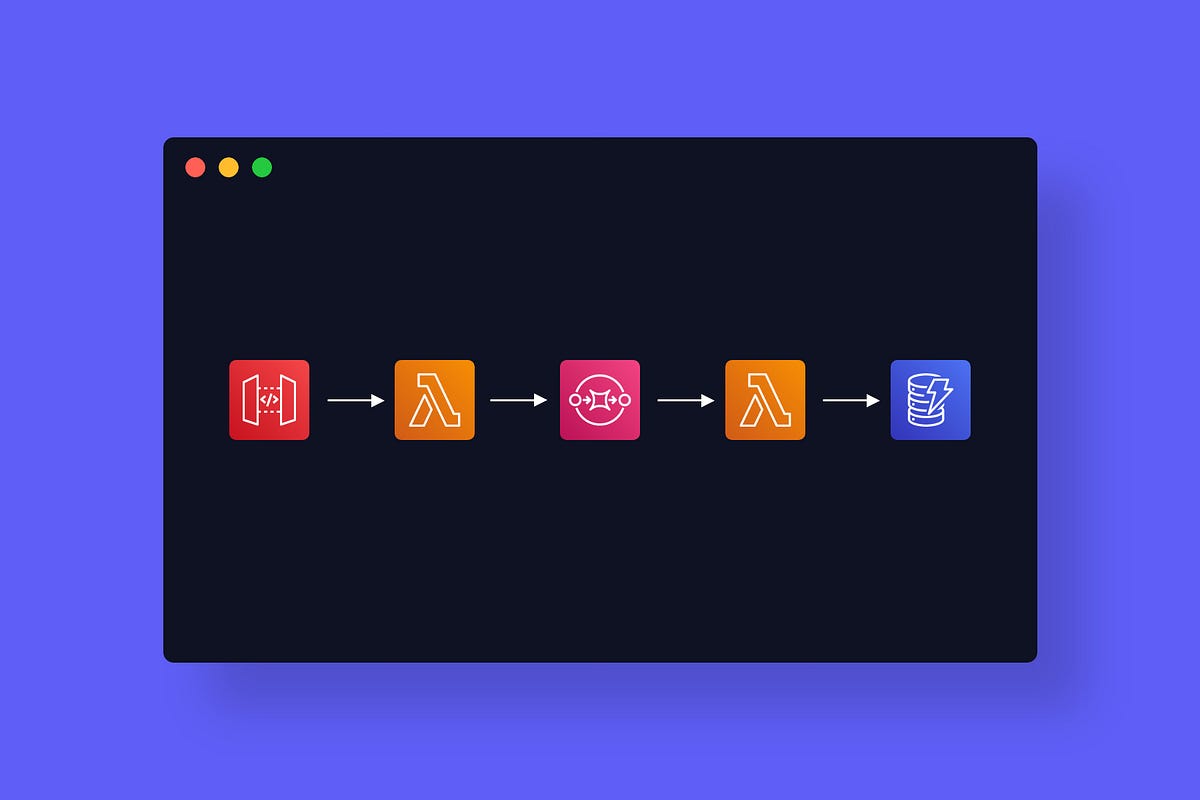
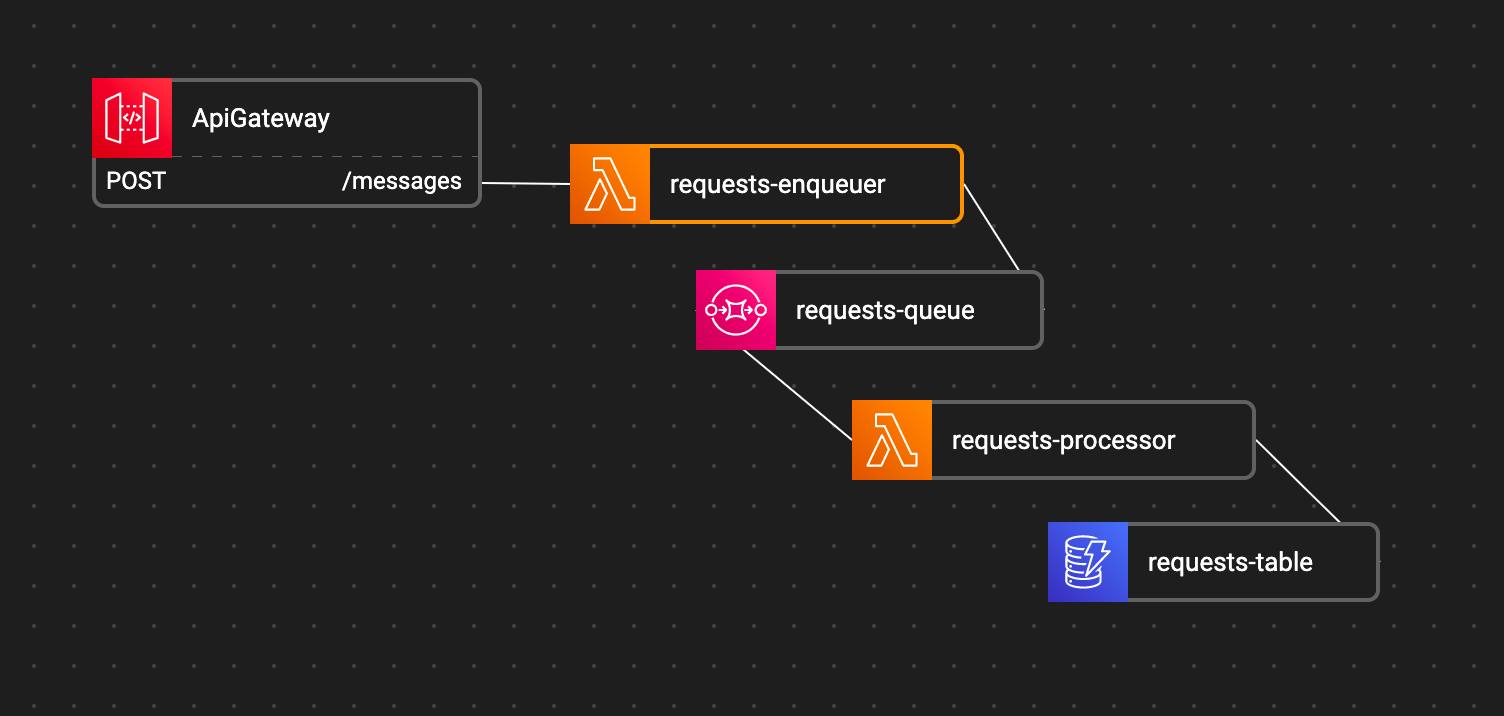
What we’re going to use:
1. API Gateway to receive our calls
2. An enqueuing Lambda function to validate and write the request into the Queue
3. An SQS queue to hold all the messages until we can handle them
4. A processing Lambda function to do the actual work in the rate we need
5. A high-frequency DB to keep all the data we collected from the events — We’ll use a simple DynamoDB table for this case.
This is how the Altostra Blueprint would look like:
The sample code for the enqueue function
#sqs-lambda #serverless #altostra #aws-sqs