Neural networks are, without a doubt, the most popular machine learning technique that is used nowadays. So, I think it is worth understanding how they actually learn.
To do so, let us first take a look at the image below:
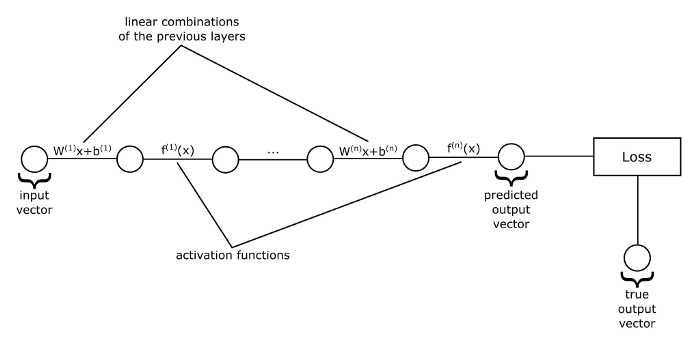
If we represent the input and output values of each layer as vectors, the weights as matrices, and biases as vectors, then we get the above-flattened view of a neural network which is just a sequence of vector function applications. That is, functions that take vectors as input, do some transformation on them, and they output other vectors. In the image above, each line represents a function, which can be either a matrix multiplication plus a bias vector, or an activation function. And the circles represent the vectors on which these functions operate.
For example, we start with the input vector, and then we feed it into the first function, which computes linear combinations of its components, then we obtain another vector as output. This last vector we feed as input to the activation function, and so on until we get to the last function in our sequence. The output of this last function will be the predicted value of our network.
We have discussed so far how a neural network gets its output, which we are interested in, it just passes its input vector through a sequence of functions. But these functions depend on some parameters: the weights and biases.
How do we actually learn those parameters in order to obtain good predictions?
Well, let us recall what a neural network actually is: it is just a function, a big function composed of smaller ones that are applied in sequence. This function has a set of parameters that, because at first, we have no idea what they should be, we just initialize them randomly. So, at first, our network will give us just random values. How can we improve them? Before attempting to improve them, we first need a way of evaluating the performance of our network. How are we supposed to improve the performance of our model if we do not have a way to measure how good or how bad is it doing?
For that, we need to come up with a function that takes as input the predictions of our network and the true labels in our dataset, and to give us a number that represents the performance of our network. Then we can turn the learning problem into an optimization problem of finding the minimum or maximum of this function. In the machine learning community, this function usually measures how bad our predictions are, hence it is named a loss function. And our problem is to find the parameters of our network that minimizes this loss function.
#2020 aug tutorials # overviews #beginners #neural networks
