What is k-Nearest Neighbor?
It is one of the simplest supervise learning techniques. If there is a new data point that we need to classify then we will choose k “closest” data points (nearest neighbors) that will be around the new data point for performing classification or regression. K can be any positive number.
KNN is a Non-parametric algorithm i.e. it does not make any underlying assumptions about the distribution of data. It is used for both classifications and regression problems.
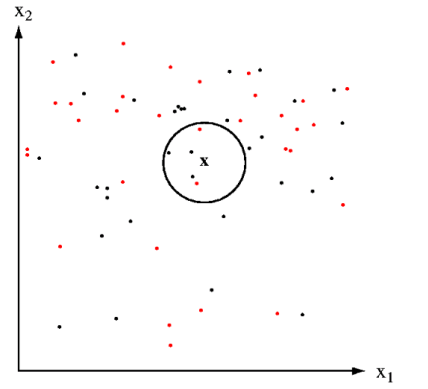
Example: We have two categorical variables red and black, and we have to classify a new data point X whether it belongs to red or black.
We select K=5 and select five close data points near to X. As you can see in the above figure in 5 data point 3 is black and 2 is red since black in a majority in number the new data point X will belong to a black class.
**KNN for Regression: **When KNN is used for regression problems the prediction is based on the mean or the median of the nearest neighbor.
**KNN for Classification: **Inclassification, the output can be calculated as the class with the highest occurrence from the K nearest neighbor.
How does the KNN algorithm works?
The KNN algorithm work with the below steps:
- Step-1: Select the number K of the neighbors
- Step-2: Calculate the distance of K number of neighbors
- Step-3: Select the K nearest neighbors as per the calculated distance.
- Step-4: Among these k neighbors, count the number of the data points in each category.
- Step-5: Assign the new data points to that category for which have the highest number.
Suppose we have a new data point and we need to put the new data point in the correct category. Consider the below image:
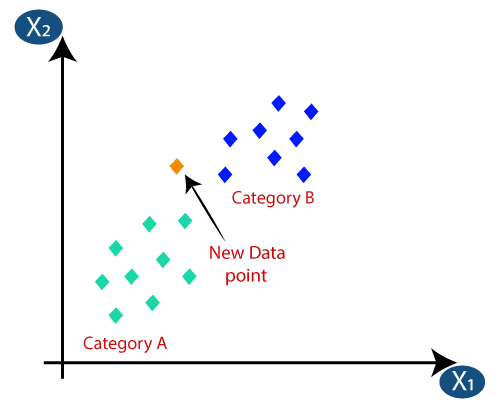
- First, we need to choose the K number of neighbors, so we will choose the k=5.
- Next, we will calculate the distance between the data points.
We can any of the three functions to calculate the distance between the data point to find the closest data point. In this example, we will use the Euclidean distance.
#knn #data-science #knn-algorithm #algorithms