Get started with Apache Spark and TensorFlow on Azure Databricks - TensorFlow is now available on Apache Spark framework, but how do you get started? It called TensorFrame
TL;DR
This is a step by step tutorial on how to get new Spark TensorFrame library running on Azure Databricks.
Big Data is a huge topic that consists of many domains and expertise. All the way from DevOps, Data Engineers to Data Scientist, AI, Machine Learning, algorithm developers and many more. We all struggle with massive amounts of data. When we deal with a massive amount of data, we need the best minds and tools. This is where the magicalcombination of Apache Spark and Tensor Flow takes place and we call it TensorFrame.
Apache Spark took over the Big Data world, giving answers and supporting Data Engineers to be a more successful while, Data Scientist had to figure their way around the limitation of the machine learning library that Spark provides, the Spark MLlib.
But no more, now, there is TensorFlow support for Apache Spark users. These tools combined makes the work of Data Scientists more productive, more accurate and faster. And taking outcome from Research to Develop to Production, faster than ever.
Before we start, let’s align the terms:
- Tensor Flow is an open source machine learning framework for high-performance numerical computations created by Google. It comes with strong support for AI: machine learning and deep learning.
- Azure Databricks is an Apache Spark-based analytics platform optimized for the Microsoft Azure cloud services platform. Azure Databricks also acts as Software as a Service( SaaS) / Big Data as a Service (BDaaS).
- TensorFrames is an Apache Spark component that enables us to create our own scalable TensorFlow learning algorithms on Spark Clusters.
1- the workspace:
First, we need to create the workspace, we are using Databricks workspace and here is a tutorial for creating it.
2- the cluster:
After we have the workspace, we need to create the cluster itself. Let’s create our spark cluster using this tutorial, make sure you have the next configurations in your cluster:
- Tensor Flow is an open source machine learning framework for high-performance numerical computations created by Google. It comes with strong support for AI: machine learning and deep learning.
- Azure Databricks is an Apache Spark-based analytics platform optimized for the Microsoft Azure cloud services platform. Azure Databricks also acts as Software as a Service( SaaS) / Big Data as a Service (BDaaS).
- TensorFrames is an Apache Spark component that enables us to create our own scalable TensorFlow learning algorithms on Spark Clusters.
The configuration:
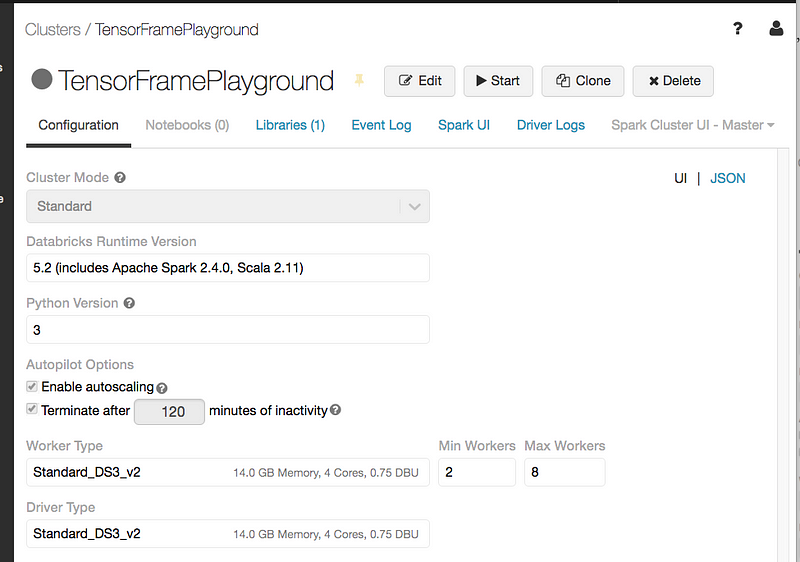
with Databricks runtime versions or above :

Press start to launch the cluster
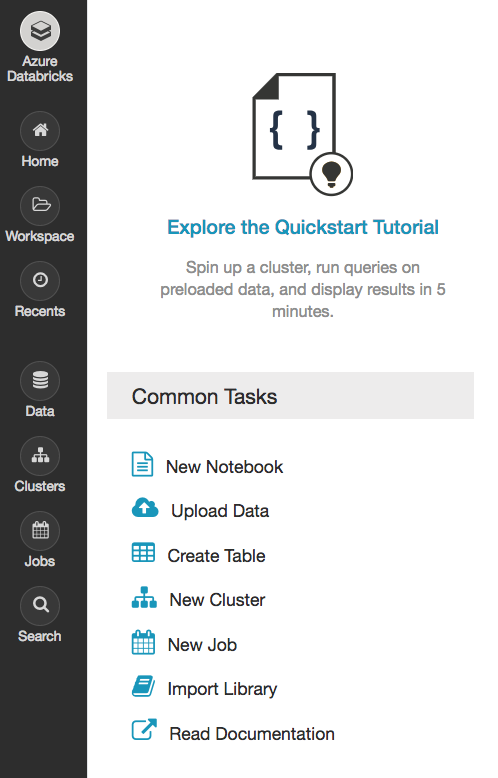
3- import the library:
Under Azure Databricks, go to Common Tasks and click Import Library:
TensorFrame can be found on maven repository, so choose the Maven tag. Under Coordinates, insert the library of your choice, for now, it will be:
databricks:tensorframes:0.6.0-s_2.11
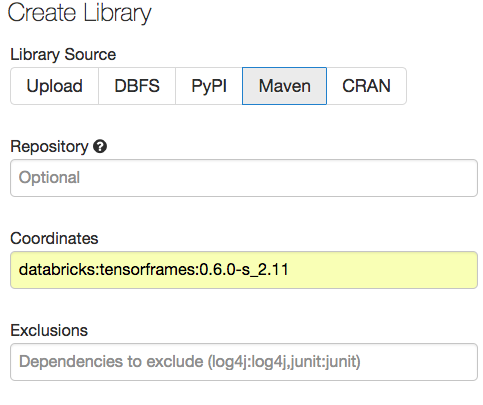
Click the Create button.
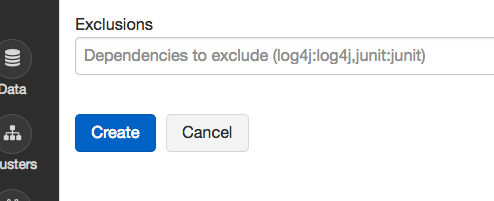
Click Install.
You will see this:
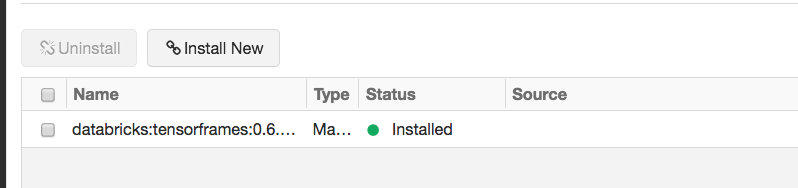
BOOM. you have TensorFrame on your Databricks Cluster.
4- the notebook:
We use the notebook as our code notebook where we can write the code and run it directly on our Spark Cluster.
Now that we have a running cluster, let’s run a notebook:
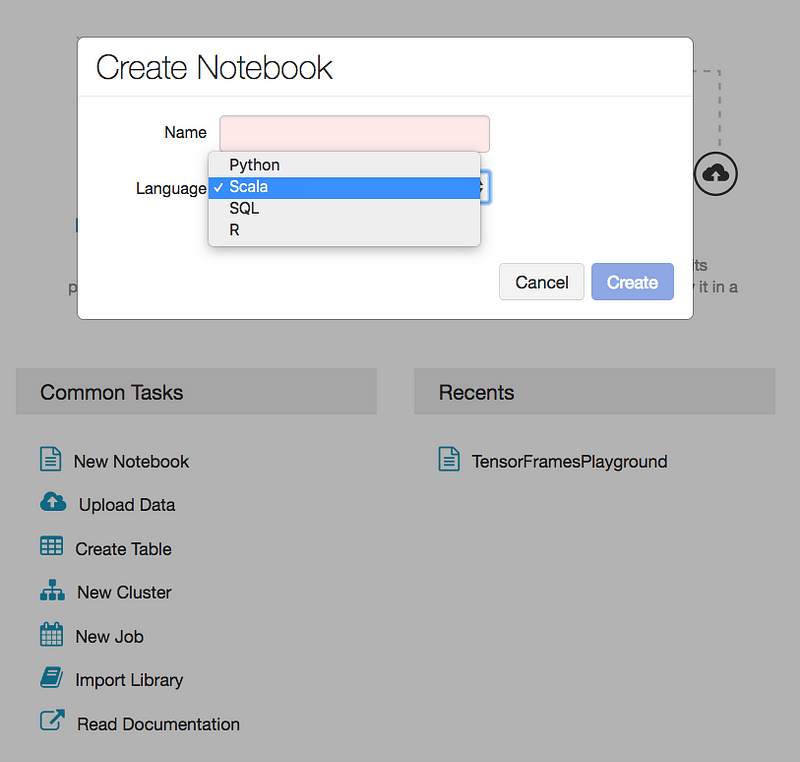
Click the New Notebook and choose the programming language of your choice ( here we chose Scala)
This is how it looks like with scala code on the notebook portal with TensorFrames:
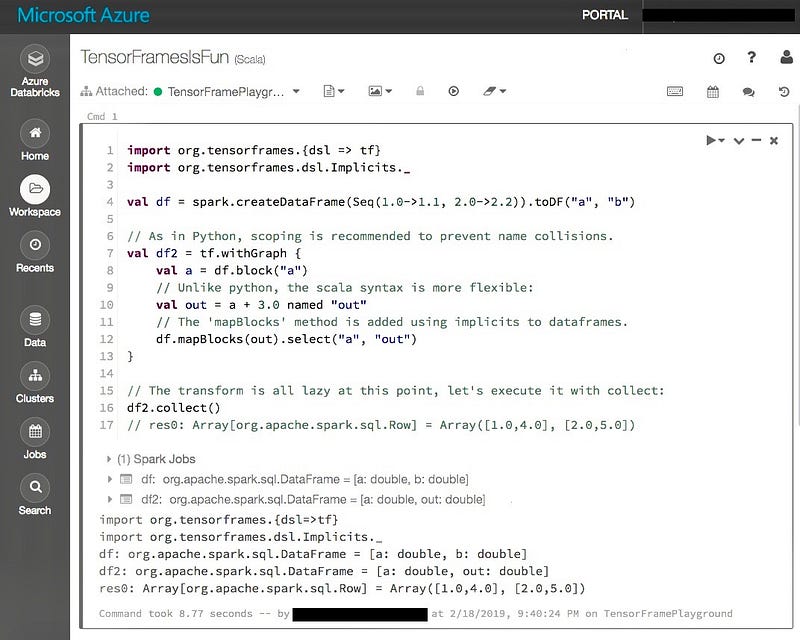
The code example is from Databricks git repository.
You can check it here as well:
import org.tensorframes.{dsl => tf}
import org.tensorframes.dsl.Implicits._
val df = spark.createDataFrame(Seq(1.0->1.1, 2.0->2.2)).toDF("a", "b")
// As in Python, scoping is recommended to prevent name collisions.
val df2 = tf.withGraph {
val a = df.block("a")
// Unlike python, the scala syntax is more flexible:
val out = a + 3.0 named "out"
// The 'mapBlocks' method is added using implicits to dataframes.
df.mapBlocks(out).select("a", "out")
}
// The transform is all lazy at this point, let's execute it with collect:
df2.collect()
// res0: Array[org.apache.spark.sql.Row] = Array([1.0,4.0], [2.0,5.0])
-The End-
Now that you have everything up and running, create your own triggered/scheduled job that uses TensorFrame in Apache Spark cluster.
and …
=================================================
Thanks for reading :heart: If you liked this post, share it with all of your programming buddies! Follow me on Facebook | Twitter
Learn More
☞ Complete Guide to TensorFlow for Deep Learning with Python
☞ Master Deep Learning with TensorFlow in Python
☞ Complete Data Science & Machine Learning Bootcamp - Python 3
☞ Machine Learning A-Z™: Hands-On Python & R In Data Science
☞ Python for Data Science and Machine Learning Bootcamp
☞ Machine Learning, Data Science and Deep Learning with Python
☞ [2019] Machine Learning Classification Bootcamp in Python
#tensorflow #apache-spark
