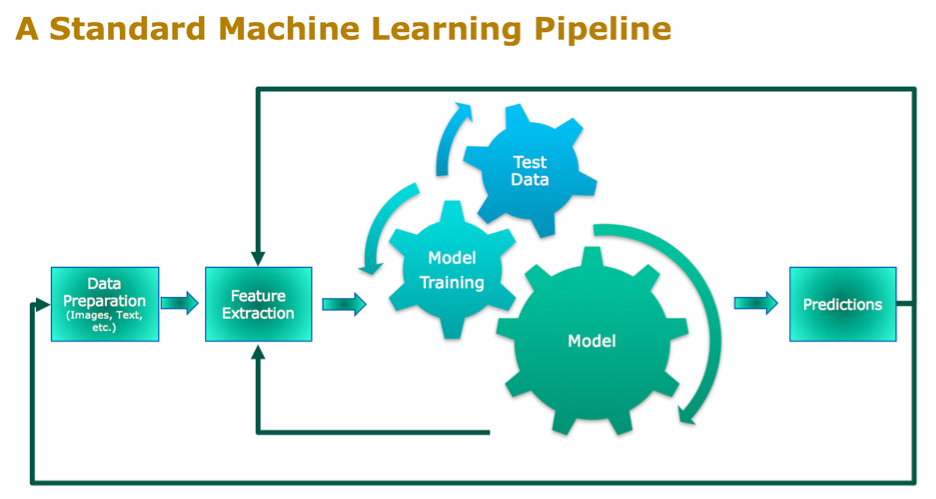
Below are the usual steps involved in building the ML pipeline:
- Import Data
- Exploratory Data Analysis (EDA)
- Missing Value Imputation
- Outlier Treatment
- Feature Engineering
- Model Building
- Feature Selection
- Model Interpretation
- Save the model
- Model Deployment *
Problem Statement and Getting the Data
I’m using a relatively bigger and more complicated data set to demonstrate the process. Refer to the Kaggle competition — IEEE-CIS Fraud Detection.
#ai #analytics #data-analysis #machine-learning #data-science
1.25 GEEK