Just when we thought that all name variations of BERT were taken (RoBERTa, ALBERT, FlauBERT, ColBERT, CamemBERT etc.), along comes AMBERT, another incremental iteration on the Transformer Muppet that has taken over natural language understanding. AMBERT was published on August 27 by ByteDance, the developer of TikTok and Toutiao.
AMBERT proposes a simple twist to BERT: tokenize the input twice, once with a fine-grained tokenizer and once with a coarse-grained tokenizer.
This article is mostly a summary of the AMBERT paper meant to distill the main ideas without the nitty-gritty details, but I will occasionally chime in with personal observations. I will prefix my own comments / ideas with the 🤔 emoji.
AMBERT also happens to be a type of French cheese, named after the French commune. Please forgive my cheesy pun. Photo by Alice Donovan Rouse on Unsplash.
The core idea: two-way tokenization
AMBERT proposes a simple twist to BERT: tokenize the input twice, once with a fine-grained tokenizer (sub-word or word level in English, character level in Chinese) and once with a coarse-grained tokenizer (phrase level in English, word level in Chinese). The hope is to leverage the best of both worlds. The former implies a smaller vocabulary, fewer out-of-vocabulary tokens, more training data per token, and thus better generalization. The latter is meant to fight strong biases that attention-based models learn with fine-grained tokenization. For instance, the token “new” will strongly attend to “york” even when their co-existence in a sentence is unrelated to New York (e.g. “A new chapel in York Minster was built in 1154”).
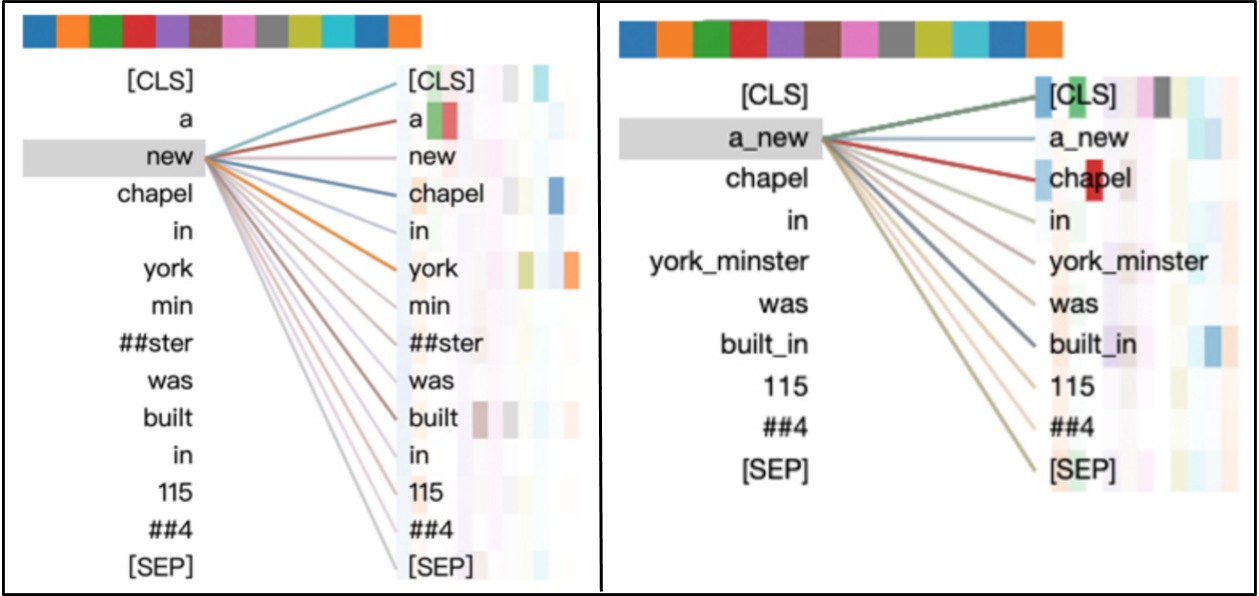
Self-attention in the sentence “A new chapel in York Minister was built in 1154”. Left: fine-grained tokenization. Right: coarse-grained tokenization. With fine-grained tokenization, “new” mistakenly attends to “york”. With coarse-grained tokenization, “a_new” correctly attends to “chapel”. Adapted from Figures 1 and 2 in the paper.
The example above shows that, when the fine-grained “a” and “new” tokens are concatenated into a single coarse-grained “a_new” token, the model correctly directs its attention to “chapel”.
As the authors of the paper note, coarse-grained tokenization cannot always be perfect — longer tokens imply more ambiguity on how to group characters into tokens. 🤔 For instance, consider an input like “I’m dreaming of a New York with endless summers”. It’s possible that the tokenizer above would mistakenly produce two tokens “a_new” and “york”. The hope is that, in this particular case, the model will trust the fine-grained “a” / “new” / “york” tokenization more.
The two inputs share a BERT encoder
A forward pass through the model consists of the following two steps:
- **text tokens → token embeddings (via separate weights): **Each list of tokens (one fine-grained, one coarse-grained) is looked up in its own embeddingmatrix and turned into a list of real-valued vectors.
- **token embeddings → contextual embeddings (via shared weights): ** The two real-valued vectors are fed into _the same _ BERT encoder (a stack of Transformer layers) — which can be done either sequentially through a single encoder copy, or in parallel through two encoder copies with tied parameters. This results in two lists of per-token contextual embeddings.
#machine-learning #bert #naturallanguageprocessing #data-science #nlp