These are the lecture notes for FAU’s YouTube Lecture “Deep Learning”. This is a full transcript of the lecture video & matching slides. We hope, you enjoy this as much as the videos. Of course, this transcript was created with deep learning techniques largely automatically and only minor manual modifications were performed. If you spot mistakes, please let us know!
Navigation
Previous Lecture** / Watch this Video / Top Level / **Next LectureThanks for tuning in to the next video of deep learning. So, what I want to show you in this video are a couple of limitations of deep learning. So, you may wonder are there any limitations? Are we done yet? Aren’t we learning something here that will solve all of the problems?

Positive examples for image captioning. Image under CC BY 4.0 from the Deep Learning Lecture.
Well of course there are some limitations. For example tasks like image captioning yield impressive results. You can see that the networks are able to identify the baseball player, the girl in a pink dress jumping in the air, or even people playing the guitar.
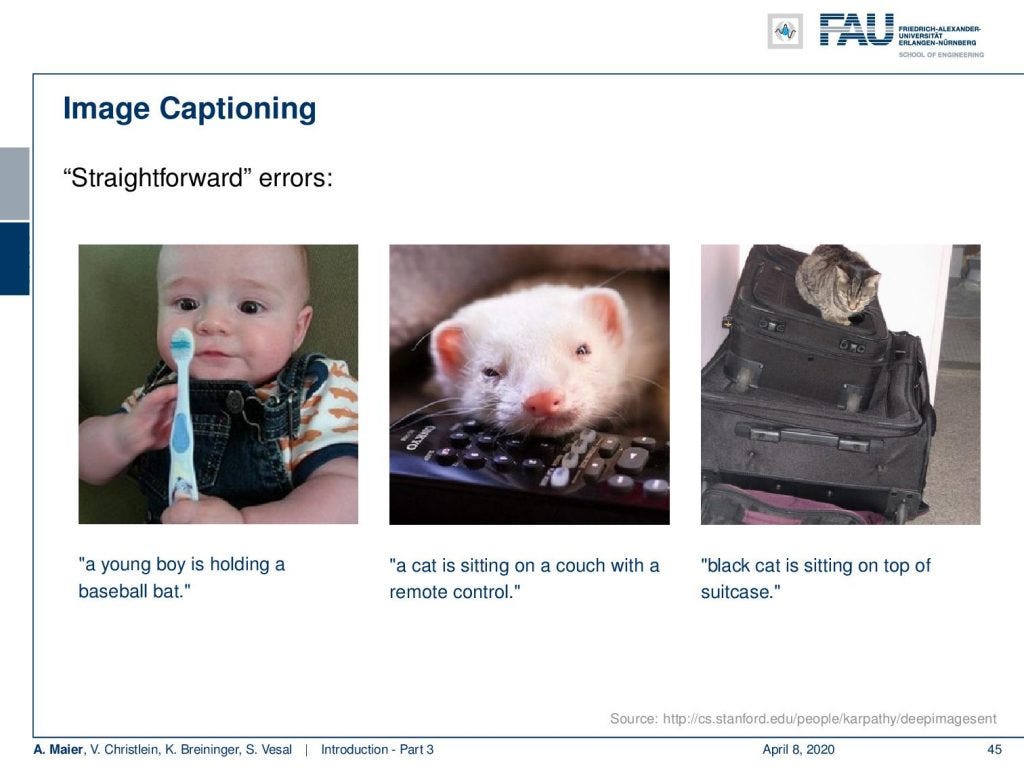
Errors in image captioning. Image under CC BY 4.0 from the Deep Learning Lecture.
So let’s look at some errors. Here on the left, you can see, this is clearly not a baseball bat. Also, this isn’t a cat in the center image and they are also slight errors like the one on the right-hand side: The cat on top of the suitcases isn’t black.

Clear errors in image captioning: Image under CC BY 4.0 from the Deep Learning Lecture.
Sometimes they’re even plain errors like here in the left image: There, I don’t see a horse in the middle of the road and also on the right image there is no woman holding a teddy bear in front of a mirror.So, the reason for this is of course there’s a couple of challenges and one major challenge is training data. Deep learning applications require huge manually annotated data sets and these are hard to obtain. Annotation is time-consuming and expensive and often ambiguous. So, as you’ve seen already in the image net challenge, sometimes it’s not clear which label to assign, and obviously you would have to assign a distribution of labels. Also, we see that even in the human annotations, there are typical errors. What you have to do in order to get a really good representation of the labels, you actually have to ask two or even more experts to do the entire labeling process. Then, you can find out the instances where you have a very sharp distribution of labels. These are typical prototypes and broad distributions of labels are images where people are not sure. If we have such problems, then we typically get a significant drop in performance. So the question is how far can we get simulations for example to expand training data.Of course, there are also challenges with trust and reliability. So, verification is mandatory for high-risk applications, and regulators can be very strict about those. They really want to understand what’s happening in those high-risk systems. End-to-end learning essentially prohibits to identify how the individual parts work. So, it’s very hard for regulators to tell what part does what and why the system actually works. We must admit at this point that this is largely unsolved to a large degree. It’s difficult to tell which part of the network is doing what. Modular approaches that are based on classical algorithms may be one approach to solve these problems in the future.
#lecture-notes #deep-learning #deep learning
