This is the third part of a series of posts showing the improvements in NLP modeling approaches. We have seen the use of traditional techniques like Bag of Words, TF-IDF, then moved on to RNNs and LSTMs. This time we’ll look into one of the pivotal shifts in approaching NLP Tasks — Transfer Learning!
The complete code for this tutorial is available at this Kaggle Kernel
ULMFit
The idea of using Transfer Learning is quite new in NLP Tasks, while it has been quite prominently used in Computer Vision tasks! This new way of looking at NLP was first proposed by Howard Jeremy, and has transformed the way we looked at data previously!
The core idea is two-fold — using generative pre-trained Language Model + task-specific fine-tuning was first explored in ULMFiT (Howard & Ruder, 2018), directly motivated by the success of using ImageNet pre-training for computer vision tasks. The base model is AWD-LSTM.
A Language Model is exactly like it sounds — the output of this model is to predict the next word of a sentence. The goal is to have a model that can understand the semantics, grammar, and unique structure of a language.
ULMFit follows three steps to achieve good transfer learning results on downstream language classification tasks:
- General Language Model pre-training: on Wikipedia text.
- Target task Language Model fine-tuning: ULMFiT proposed two training techniques for stabilizing the fine-tuning process.
- Target task classifier fine-tuning: The pretrained LM is augmented with two standard feed-forward layers and a softmax normalization at the end to predict a target label distribution.
Using fast.ai for NLP -
fast.ai’s motto — Making Neural Networks Uncool again — tells you a lot about their approach ;) Implementation of these models is remarkably simple and intuitive, and with good documentation, you can easily find a solution if you get stuck anywhere. Along with this, and a few other reasons I elaborate below, I decided to try out the fast.ai library which is built on top of PyTorch instead of Keras. Despite being used to working in Keras, I didn’t find it difficult to navigate fast.ai and the learning curve is quite fast to implement advanced things as well!
In addition to its simplicity, there are some advantages of using fast.ai’s implementation -
- Discriminative fine-tuning is motivated by the fact that different layers of LM capture different types of information (see discussion above). ULMFiT proposed to tune each layer with different learning rates, {η1,…,ηℓ,…,ηL}, where η is the base learning rate for the first layer, ηℓ is for the ℓ-th layer and there are L layers in total.
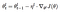
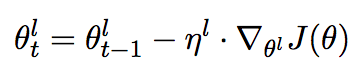
Weight update for Stochastic Gradient Descent (SGD). ∇θ(ℓ)J(θ) is the gradient of Loss Function with respect to θ(ℓ). η(ℓ) is the learning rate of the ℓ-th layer.
- Slanted triangular learning rates (STLR) refer to a special learning rate scheduling that first linearly increases the learning rate and then linearly decays it. The increase stage is short so that the model can converge to a parameter space suitable for the task fast, while the decay period is long allowing for better fine-tuning.

Learning rate increases till 200th iteration and then slowly decays. Howard, Ruder (2018) — Universal Language Model Fine-tuning for Text Classification
Let’s try to see how well this approach works for our dataset. I would also like to point out that all these ideas and code are available at fast.ai’s free official course for Deep Learning.
#nlp #machine-learning #transfer-learning #deep-learning #deep learning
