You don’t need a linear regressor to recognize one of the core tenants of data science — bad data leads to a bad study. This was vividly demonstrated in my second project with Metis data science bootcamp, a linear regression model designed to predict the gross of a Broadway play or musical adapted from a film based on the commercial success of said film. In this article, we’ll talk about data purity, and why a lack of it in this study led to a model that isn’t quite yet meant for the stage.
(For anyone interested in the nuts and bolts, check out the project repo!)
What is data purity?
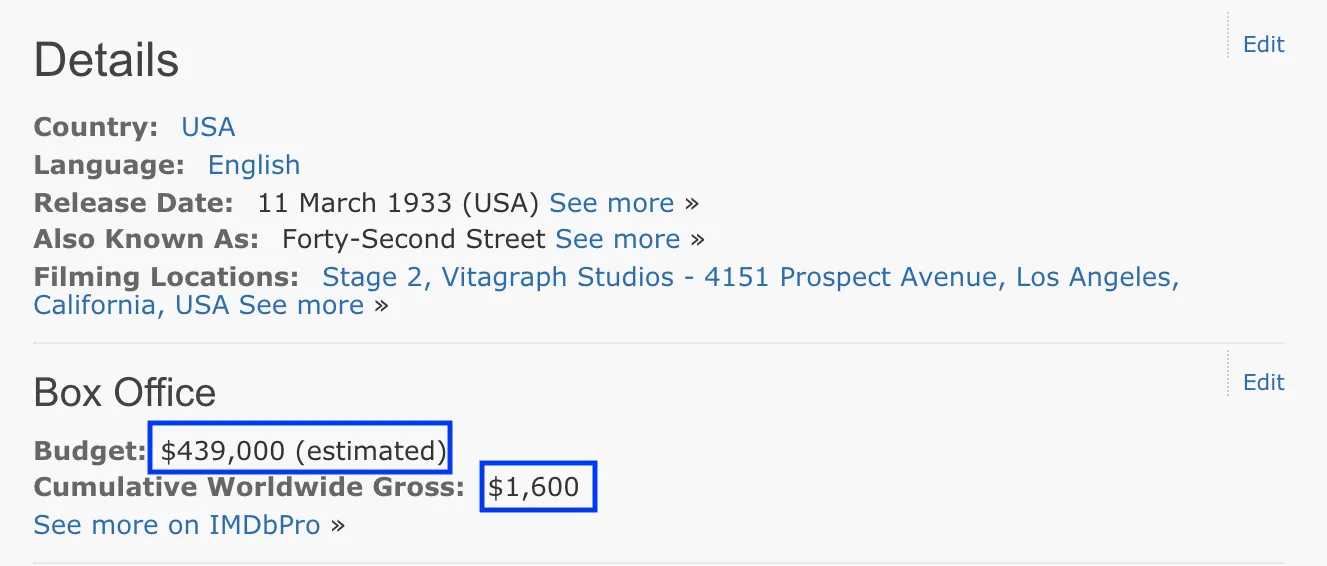
Data purity is a term I first encountered while learning SQL, referring specifically to a value in a column being out of range of that column. If you have a column with numbers representing day of the week, any number greater than 7 would be considered impure. There are seven days in a week, so any number beyond that must come from a computational or human error along the way. This doesn’t necessarily represent _outliers _(like “1” representing Monday in a table full of weekend days — 6 and 7’s) but more refers to numbers that are logically and statistically impossible (-9, or 900).
Data purity becomes of particular concern when you’re working with data scraped from the web. Web scraping, a meticulous but oddly satisfying task, is best described as coding thousands of little bots to go into webpages and extract data. It is also necessary for some enormous data collection task — like scraping information from 10,000+ IMDB pages, for example. This was my first step in my project, and I was interested, among other features, specifically in the budget and the domestic and worldwide gross of each film. These variables are considered features, probably referred to by your high school science teacher as an independent variable.
#theatre #broadway #data-science #data-accuracy #python