In computer science, a B-tree is a self-balancing tree data structure that keeps data sorted and allows searches, sequential access, insertions, and deletions in logarithmic time. Postgres has a few index types but B-trees are by far the most common. They’re good for sorting and matching
Full Article: http://www.entradasoft.com/blogs/climbing-b-tree-indexes-in-postgres
Here is a quick overview of what types of index(s) available to use in your tables:
· B-Tree: The default for Postgres.
· GIN: For JSONB and arrays. As inverted indexes, they contain an index entry for each word, with a compressed list of matching locations.
· GiST : For full text search and geospatial datatypes. A GiST index is lossy, meaning that the index might produce false matches.
· SP-GiST : For larger datasets with natural but uneven clustering
· **BRIN **(Block Range Index) : For really large datasets that line up sequentially. E.g. orders might have a date column, and most of the time the entries for earlier orders appear earlier in the table.
· Hash: The query planner will consider using a hash index whenever an indexed column is involved in a comparison using the = operator.
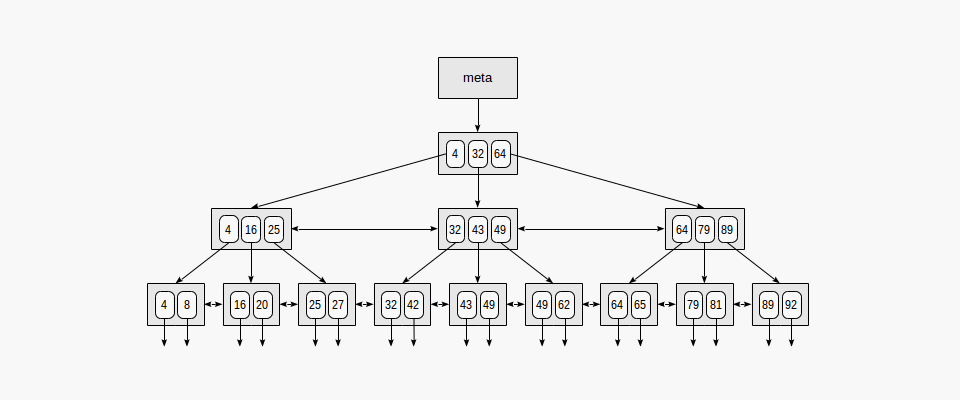
The Structure of a B-tree
Basically, it’s a data structure that sorts itself. That’s why it’s self-balancing — it chooses it’s shape on it’s own.The B-tree is a generalization of a binary search tree in that a node can have more than two children. Unlike self-balancing binary search trees, the B- tree is optimized for systems that read and write large blocks of data.
B-trees are “balanced” because the distance from the root to any leaf node is the same. A leaf node is a node without children. The root node is the node at the top. B-Tree is a tree where each node can have multiple children, or better said, a B-Tree can have N children. While in binary search trees each node can have one value, B-Trees have the concept of keys. Keys are like a list of values, that each of the nodes will hold.
Let’s draw it out:
The most important thing about B-Trees is their balancing aspect. The concept revolves on the fact that each node has keys, like in the example above. The way B-Trees balance themselves is really interesting, and the keys are the most important aspect of this this functionality.
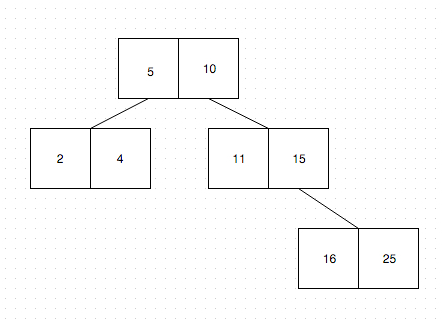
Basically, whenever a new item (or, in our case, a number) is added, the B-Tree finds the appropriate place (or, node) for the item to go in. For example, if we want to add the number 6, the B-Tree will “ask the root node”, in what node should it push the number in. “Asking” is nothing more than comparing the new number with the keys of the node. Since the number 6 is larger then 5, but smaller then the number 10 (which are the root node keys), it will create a new node just below the root node:
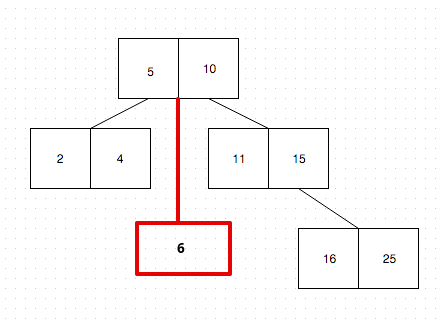
With this mechanism, the B-Tree is always ordered and looking up a value in it is rather cheap.
Now if we wanted to look up the key, 6, we’d compare 6 to values in the root node and see that it’s between 5 and 10. So we’d use the pointer between 5 and 10 to find the node containing 6.
This is an abstraction over Postgres’ implementation but you can already imagine why this is faster than iterating over every number in a table and checking if it equals 6.
This is why B-trees can search, insert and delete in O(logN) time.
Limitations
Almost in all use cases, the power of indexes is noticeable on large amounts of data. This means that the indexes will have to be as big as the actual data tables. Or does it?
Imagine if we are dealing with billions of records. This means that the index tables will have the billions of records stored in an ordered fashion. Okay, PostgreSQL could handle that. But, can you imagine how long would an INSERT command take? Adding the record in the data table will take really long, because the index will have to add the new record in the correct place, to keep the order of the indexes. Due to this limitation, the implementation of the B-Tree index keeps page files, which simply put, are nodes on a big B-Tree data structure.
Syntax:
— Create an index column using btree on the purchase table
— CREATE INDEX <<index_name>> ON <<table_name>> USEING <<index_type>>
#sql #search #postgres #b-tree #indexing