Every day, people try to live up to computer science savants and try to break into the field of Data Science.
How hard is it? What does it take? Where do I start?
In this blog I’ll summarize the 3 hardest challenges I faced doing my first Data Science project in this Kaggle Notebook:
- You know nothing
- Data preparation is critical and time-consuming
- Interpret your results
Opinions are my own.
Before getting into any details, there is quite an essential part that people seem to gloss over during explanations, or they’re simply part of their small snippet codes. In order for you to use any of the advanced libraries, you are going to have to import them into your workspace. It is best to collect them at the top of your workbook.
My example below:
# Import all the necessary libraries
# commonly used libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
# visualization library
import seaborn as sns
# data manipulation utility libraries
import distutils
import datetime
import re
# sklearn libraries
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
from sklearn import metrics
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score, mean_squared_error
# stats library
from scipy import stats
from scipy.stats import boxcox
You know nothing
For my first Data Science project, I created a short blog on starting an Airbnb in Amsterdam. I only used basic data analysis methods and regression models.
Regression models are probably the most basic parts of data science. A typical linear regression function will look like this:
# import library
from sklearn.linear_model import LinearRegression
def fit_linear_mod(df, response_col, test_size=.3, rand_state=0):
#Split into explanatory and response variables
X = df.drop(response_col, axis=1)
y = df[response_col]
#Split into train and test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size, random_state=rand_state)
lm_model = LinearRegression(normalize=True) # Instantiate
lm_model.fit(X_train, y_train) #Fit
#Predict using your model
y_test_preds = lm_model.predict(X_test)
y_train_preds = lm_model.predict(X_train)
#Score using your model
test_score = r2_score(y_test, y_test_preds)
train_score = r2_score(y_train, y_train_preds)
return test_score, train_score, lm_model, X_train, X_test, y_train, y_test, y_test_preds, y_train_pred
This will return several outputs that you will then use to evaluate your model performance.
There are more than 40 techniques used by data scientists. This means I only used 2.5% of all the models out there.
I’ll be generous. Given my statistics course in University 8 years ago, going into this project I knew about 10% of that regression model already. That means I knew 0.25% of the entire body of knowledge that I know is out there. Then add a very large amount of things I don’t know I don’t know.
My knowledge universe in Data Science looks something like this:
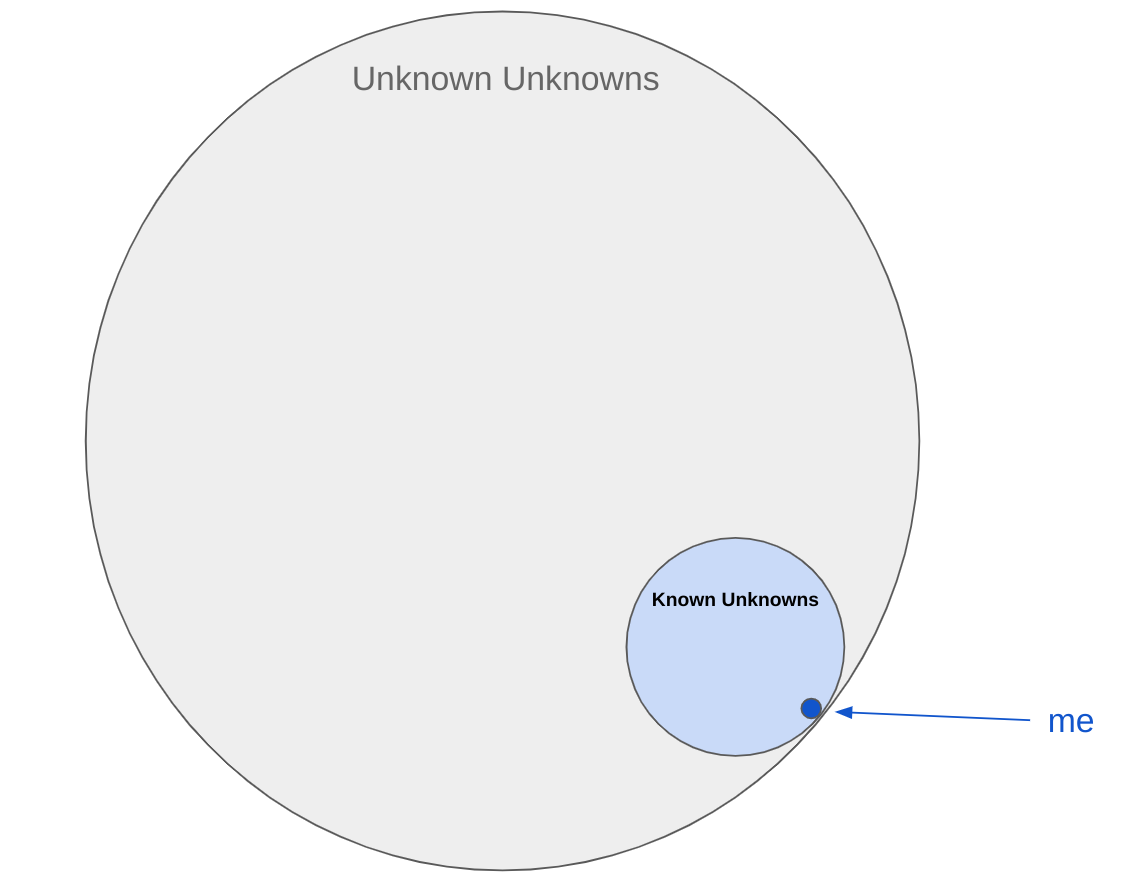
Like that isn’t bad enough, you will find articles like these, exactly describing all of your shortcomings.
This current project took me about 4 weeks and let’s say that’s a pretty average rate of learning new data science models. It will take me about 4 / 0.25% = 800 weeks to learn all the models I have heard of so far and probably add another 5 times that time to learn (probably not even close to) everything in the data science field.
#data-science-training #data #learning-to-code #data-science
