The Falcon 9, developed by aerospace company SpaceX, means it is now possible to reuse the first-stage of the rocket, by flying it safely back to Earth.
An achievement once seemed so impossible that it lead creation of multiple “fake SpaceX landing videos-explanations” now is widely agreed upon about how amazing behind the tech related to it.
While today I’m not here nor capable of you giving rocket engineering course just wanted to show this quick little diagram from SpaceX to understand a little bit more.

[You can check more about in video form here]
While none of AI techniques have been deployed to any of SpaceX tech pipeline (they are using classic-robotics/control theory way of path planning algorithms) it would be nice to see what would happen if we tried to solve the problem with_ state of the art_ Reinforcement Learningalgorithms.
The Environment
If you are new to RL I urge you to checkout other tutorials,books and resources for beginners relating to learning more about fundamentals of RL and the math about it.
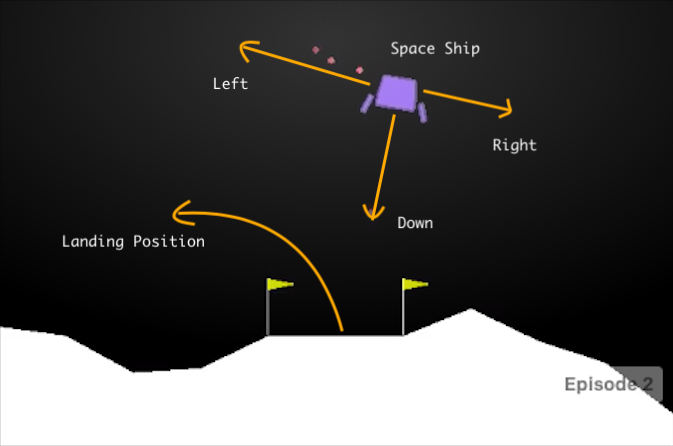
Dear Sven Niederberger(@EmbersArc on GitHub) created this tough Reinforcement Learning environment some time ago. While in creation it’s main purpose was to create a nice attractive/hype GYM like environment using ideas from LunarLander envs , it quickly has been realized it’s way harder to solve in terms of RL than what was inspired for it.
How does LunarLander works,ref mc.ai
LunarLander has 2 versions. One designed for discrete action space
- 0– Do nothing
1– Fire left engine2– Fire down engine3– Fire right engine
other for continuous action space
Action is two real values vector from -1 to +1.
- First controls main engine, -1…0 off, 0…+1 throttle from 50% to 100% power. Engine can’t work with less than 50% power.
- Second value -1.0…-0.5 fire left engine, +0.5…+1.0 fire right engine, -0.5…0.5 off.
While discrete action one easily can be solved with Value based methods plus non linear functional approximation such as DQN,Rainbow DQN or Gorilla DQN , continuous action problem requires somekind of actor-critic based algorithm to work due sparse rewards, hard exploration and unstable nature of vanilla DQN methods.
PPO+LSTM + paralel train(on policy,cluster style training), Soft Actor Critic(SAC,off policy), DDPG and D4PG(off policy- hybrid actor critic methods) can be used for solving this problem. Especially if you are going for a on policy methods I would urge to you take a look on parallelization and LSTMs(or Attention mechanisms for being SOTA?) with RL in general but that’s a topic for another day.
Our Rocket gym also uses most of things from LunarLander setup and it’s highly customizable structure.It uses Box2D as physics backend and openGL for light rendering of environment(images aren’t used in observations just there for checking your progress)
#control #rockets #spacex #reinforcement-learning #deep-learning #deep learning
