This article contains detailed implementation steps of Collaborative Filtering in python without any external libraries from scratch.
As the name suggests, this is a part 2 of the Recommendation System article where part 1 focuses over content based recommendation system, this article will focus over collaborative filtering approach i.e. Harnessing quality judgments of other users.
_The main idea in collaborative filtering revolves around predicting the rating of an item for user __X _based on the ratings given by a set of similar users.
Let us try to understand this definition, here ‘similar users’ refer to a set of users that have similar likeness and dis-likeness as user X’s. So, for example if user x has disliked an item a then the similar users must also dislike the item _a _and vice versa. Although, the strength of their similarity depends upon the ratings provided by the users. Fig 2 describes this process where we are trying to predict likable items for Mr. A.
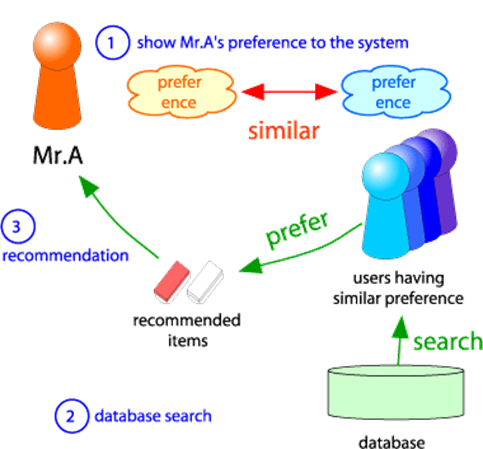
Fig. 2
Once we have a set of users that have rated the items in a similar way as of user X then we can start predicting the ratings for the items that have yet not been used by the user _X _and the items with highest ratings will be recommended to the user X. This approach is also known as user-user based collaborative filtering as we are matching user profiles and not item profile in that case it would be item-item based collaborative filtering.
Sounds simple! Well let’s try to implement it.
Data Set:
I am using the same data set as used in part 1 i.e. anime dataset from Kaggle. The data-set contains two files rating.csv having user’s rating for different anime so total 3 columns and anime.csv which is containing details for all the anime like name, type, average ratings, etc. There are total 12,294 unique anime, 73,516 unique users and 7,813,737 total ratings.
In this approach we will mostly use the rating.csv file i.e. the file containing ratings given by each user to some anime. There are missing values -1, for user indicating that the user has watched this anime but has not rated it. The global average rating is 7.8.
Implementation Steps:
The implementation is mainly divided into 3 tasks:
**Task 1: **To calculate a set of similar users as of user X. And for calculating the similarity between two users we have used Pearson Correlation Coefficient between user x with rest of all users. Once done, it will return a list of N most similar users.
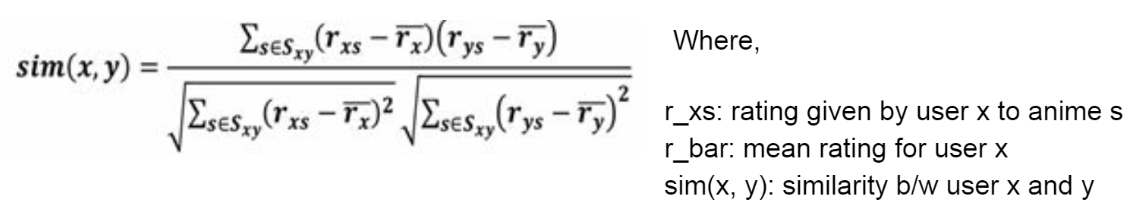
Fig. 2 (Pearson Correlation Coefficient)
**Task 2: **After getting a list of similar users as user X we can predict the ratings of the anime that the user _X _has not watched but similar users from the set N have watched.
#anime #big-data-analytics #recommendation-system #collaborative-filtering #machine-learning #deep learning