Web Scraping is the most important concept of data collection. In Python, BeautifulSoup, Selenium and **XPath **are the most important tools that can be used to accomplish the task of web scraping.
In this article, we will focus on BeautifulSoup and how to use it to scrape GDP data from Wikipedia page. The data we need on this site is in form of a table.
Definition of Concepts
Take a look at the following image then we can go ahead and define the components of an HTML table
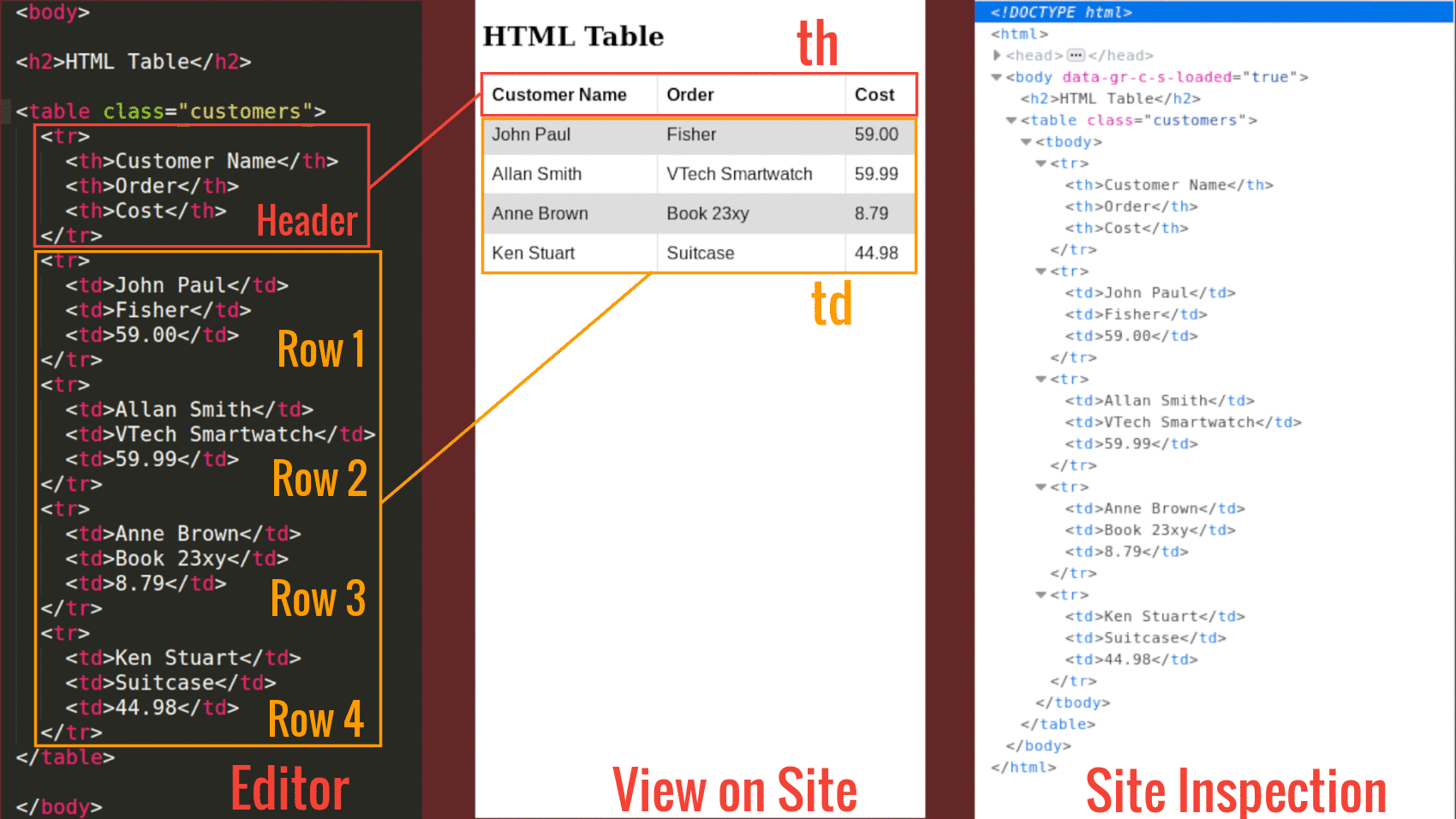
From the above image we can deduce the following:
The tag defines an HTML table.
An HTML table consists of one
Our interest is to inspect the elements of a given site (in this case the site we want to scrap — on the far right of Figure 1 shows the elements of the site). In most computers you visit the site and click **Ctrl+Shift+I **to inspect the page you wish to scrap.
Note: Elements of a web page are identified by using a class or id options on the tag. Ids are unique but classes are not. This means that a given class can identify more than one web element while one id identifies one and only one element.
Lets now see the image of the site we want to scrape
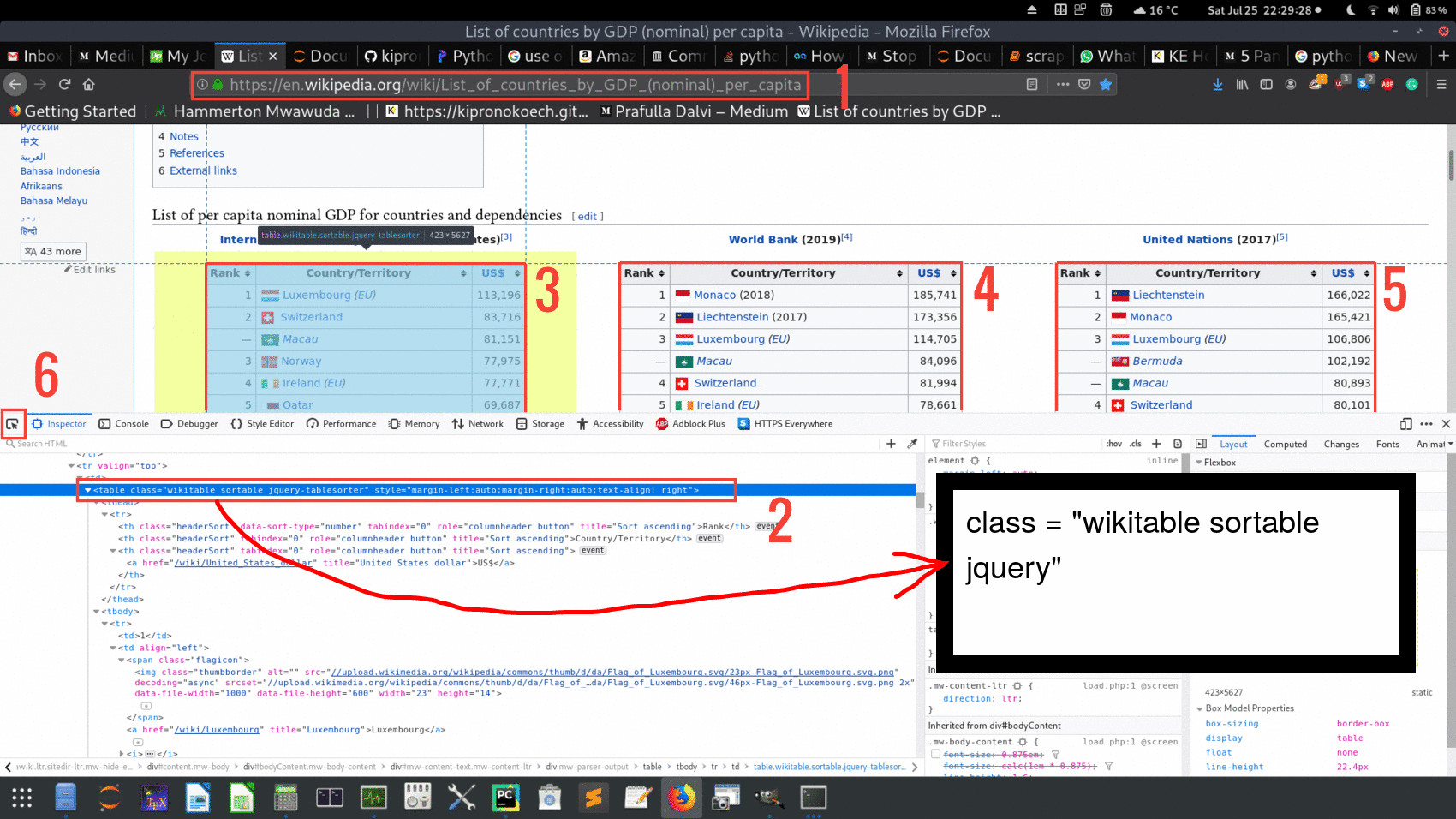
Fig 3
From this Figure note the following:
- This is the Uniform Resource Locator (URL). We need this.
- Tag element for our object of interest. The object is defined by class and not id:
class = “wikitable sortable jquery”.Note that the tag element contains 3 classes identifying one table (classes are separated by white space). Apart from general reference of a site element as we will use here, classes and ids are used as reference to support styling using languages like CSS. - In the site there are 3 tables numbered 3, 4 and 5 in the Figure above. For the sake of this article we will go through how to scrape table 3 and you can easily figure out of how to do 4 and 5.
- The button labelled 6 is very important when you are hovering through the page to identify the elements of your interest. Once your object of interest is highlighted the tag element will also be highlighted. e.g for our case label 2 is matching label 3.
Actual Scraping
Required packages: bs4, lxml, pandas and requests.
Once you have the said packages we can now go through the code.
In this snippet, we import necessary packages and parse HTML content of the site.
| , and | elements.
The |
|---|---|
| element defines a table header, and the | element defines a table cell.
An HTML table may also include |
#web-scraping #editors-pick #python #html