As I laid out in my other article BigQuery: SQL on Nested Data, working with SQL on nested data can be very performant — as long as the task is parallelizable in the back end. But if your data comes in flat tables, e.g. CSV, the data has to be transformed first.

Photo by Author
Nesting Single Values
Usually — in a flat table scenario — you’d combine two tables only on demand using a JOIN:
WITH authors AS (
SELECT 10 AS id, 'Hannah Arendt' as author UNION ALL
SELECT 11, 'Simone de Beauvoir'
),
books AS (
SELECT 10 AS id, 'On Violence' as title UNION ALL
SELECT 10, 'The Human Condition' UNION ALL
SELECT 10, 'On Revolution' UNION ALL
SELECT 11, 'The Second Sex' UNION ALL
SELECT 11, 'America Day by Day'
)
SELECT *
FROM authors
LEFT JOIN books USING(id)
view raw
med_join.sql hosted with ❤ by GitHub
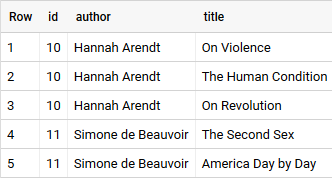
Resulting table from query above — try it out!
But of course, we’d never save a table like this because some fields are just repeated over and over again taking up storage which in turn would create avoidable costs.
But if we used table authors and put the books into an array we wouldn’t repeat author fields. In BigQuery we can easily do that using [ARRAY_AGG()](https://cloud.google.com/bigquery/docs/reference/standard-sql/functions-and-operators#array_agg) — an aggregation function you can use in combination with GROUP BY to put values into an array:
WITH authors AS (
SELECT 10 AS id, 'Hannah Arendt' as author UNION ALL
SELECT 11, 'Simone de Beauvoir'
),
books AS (
SELECT 10 AS id, 'On Violence' as title UNION ALL
SELECT 10, 'The Human Condition' UNION ALL
SELECT 10, 'On Revolution' UNION ALL
SELECT 11, 'The Second Sex' UNION ALL
SELECT 11, 'America Day by Day'
)
SELECT
author,
ARRAY_AGG(title) as works
FROM authors LEFT JOIN books USING(id)
GROUP BY author
view raw
med_join_array_agg.sql hosted with ❤ by GitHub
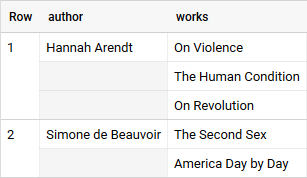
Titles nested in the “works” array — try it yourself!
If we saved this result table we would avoid costs by storing information efficiently and we could get rid of some ID’s since we don’t need to join anymore.
It also reduces the complexity of queries because information sits in the same table. You don’t have to imagine table A and table B and what they look like after joining and only then think about how to select and group — you can select and group directly.
Look at the last SELECT statement here — imagine we stored the result table somewhere instead of putting it into a WITH.
WITH authors AS (
SELECT 10 AS id, 'Hannah Arendt' as author UNION ALL
SELECT 11, 'Simone de Beauvoir'
),
books AS (
SELECT 10 AS id, 'On Violence' as title UNION ALL
SELECT 10, 'The Human Condition' UNION ALL
SELECT 10, 'On Revolution' UNION ALL
SELECT 11, 'The Second Sex' UNION ALL
SELECT 11, 'America Day by Day'
),
result AS (
SELECT
author,
ARRAY_AGG(title) as works
FROM authors LEFT JOIN books USING(id)
GROUP BY author
)
SELECT
author,
works,
ARRAY_LENGTH(works) as qtyTitles,
(SELECT SUM( LENGTH(title) ) FROM UNNEST(works) AS title) qtyCharacters
FROM result
view raw
med_use_nests.sql hosted with ❤ by GitHub
Writing sub-queries (line 24) with UNNEST() was covered in BigQuery: SQL on Nested Data
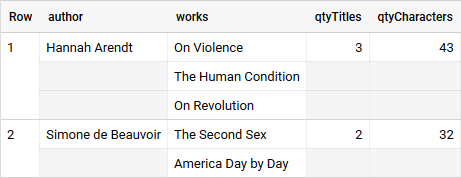
Resulting table from query above — try it!
Here, we can easily apply all kinds of aggregation techniques to the array or simply cross join the array with its parent to get a flat table. We pre-joined the table for further analyses but kept storage efficient. We even introduced two fields qtyTitles and qtyCharacters that already tell us things about the array — this is helpful for common use-cases in array aggregation.
Nesting Multiple Values
Let’s introduce another field to see how we can store multiple fields in an array. Let’s quickly think about it: we can only store one element type at a time in an array — it’s a simple list: [1,1,2,3,5,8]. So we need something that turns multiple values into one complex value. The solution to that is STRUCT which is basically a list of key-value pairs that comes with a requirement: the keys have to stay the same and the values are not allowed to change their data type: [{a:1,b:x},{a:2,b:y},{a:3,b:z}]. That’s why BigQuery is called “semi-structured”.
#sql #big-data-analytics #data-science #nested-data #bigquery #data analysis
