Big compute needs limit performance, calling for more efficiency.
GPT-3, the latest state-of-the-art in Deep Learning, achieved incredible results in a range of language tasks without additional training. The main difference between this model and its predecessor was in terms of size.
GPT-3 was trained on hundreds of billions of words — nearly the whole Internet — yielding a wildly compute-heavy, 175 billion parameter model.
OpenAI’s authors note that we can’t scale models forever:
“A more fundamental limitation of the general approach described in this paper — scaling up any LM-like model, whether autoregressive or bidirectional — is that it may eventually run into (or could already be running into) the limits of the pretraining objective.”
This is the law of diminishing returns in action.
Diminishing Returns
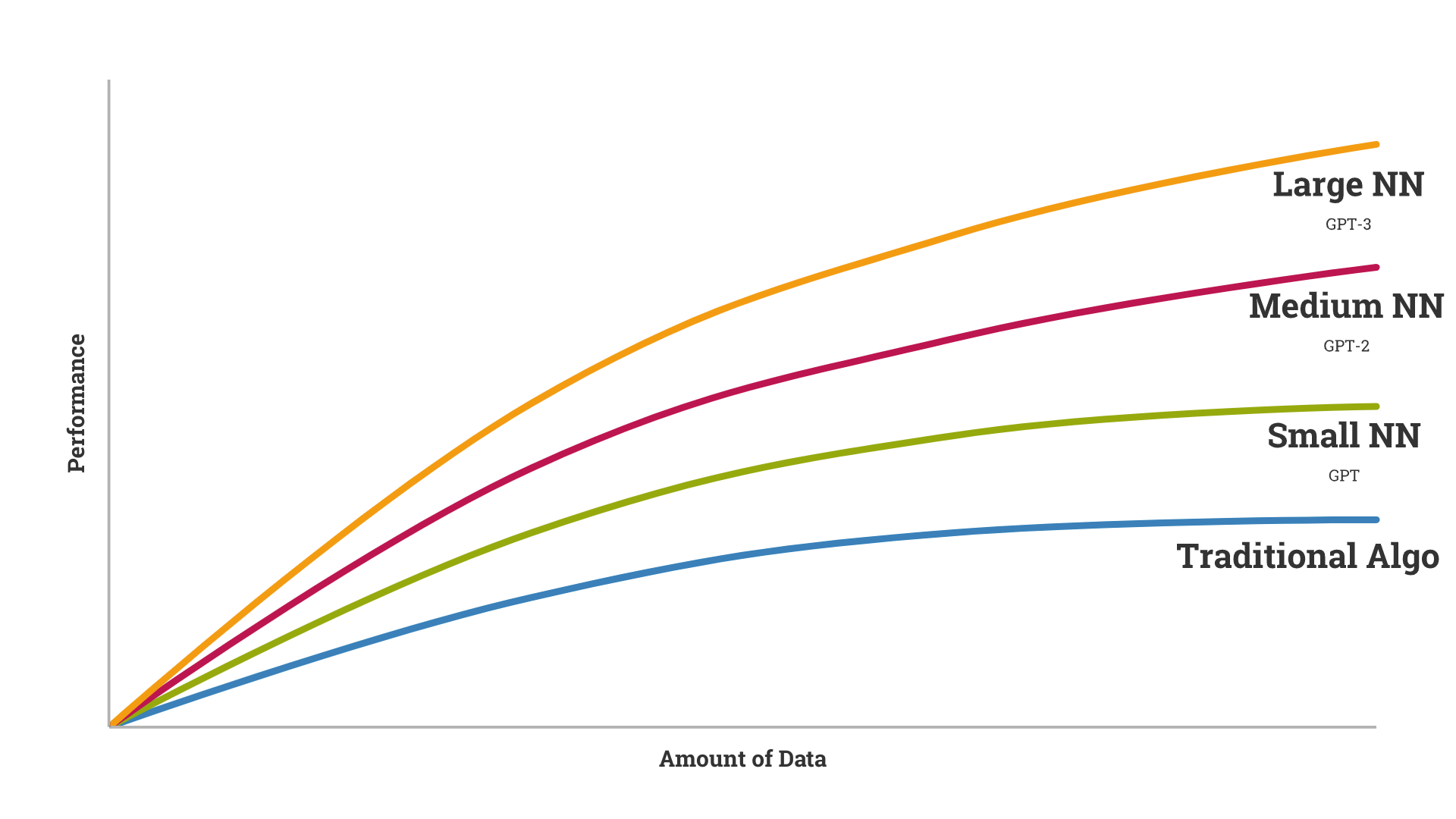
By author.
If you train a deep learning model _from scratch _with small data (not starting with ResNet or ImageNet, or some other transfer learning base), you’ll achieve lesser performance. If you train with more data, you’ll achieve more performance. GPT-3 showed that training on an enormous dataset, with a supercomputer, achieves state-of-the-art results.
Each successive GPT model improved on the last largely by scaling the training data.

Meme created by author using imgflip.
However, it’s uncertain that scaling it up again — say, 10X the data and 10X the compute — would bring anything more than modest gains on accuracy. The paper “Computational Limits in Deep Learning” lays out these problems — Deep Learning is unsustainable, as-is:
“Progress along current lines is rapidly becoming economically, technically, and environmentally unsustainable.”
This example perfectly illustrates diminishing returns:
“Even in the more-optimistic model, it is estimated to take an additional 10⁵× more computing to get to an error rate of 5% for ImageNet.”
François Chollet, the author of the wildly popular Keras library, notes that we’ve been approaching DL’s limits:
“For most problems where deep learning has enabled transformationally better solutions (vision, speech), we’ve entered diminishing returns territory in 2016–2017.”
Deep Learning: Diminishing Returns? - Semiwiki
In fact, while GPT-3 is wildly bigger than GPT-2, it still has serious shortcomings, as per the paper’s authors:
“Despite the strong quantitative and qualitative improvements of GPT-3, particularly compared to its direct predecessor GPT-2, it still has notable weaknesses,” including “little better than chance” performance on adversarial NLI.
Natural Language Inference has proven to be a major challenge for Deep Learning, so much so that training on an incredibly large corpus couldn’t solve it.
#machine-learning #technology #artificial-intelligence #deep-learning #ai