In the field of Deep Learning, datasets are an essential part of every project. To train a neural network that can handle new situations, one has to use a dataset that represents the upcoming scenarios of the world. An image classification model trained on animal images will not perform well on a car classification task.
Alongside training the best models, researchers use public datasets as a benchmark of their model performance. I personally think that easy-to-use public benchmarks are one of the most useful tools to help facilitate the research process. A great example of this is the Papers With Code state-of-the-art charts.
Another great tool is the ready-to-use dataset libraries. In this post, I will review the new HuggingFace Dataset library on the example of IMBD Sentiment analysis dataset and compare it to the TensorFlow Datasets library using a Keras biLSTM network. The story can also work as a tutorial for using these libraries.
All codes are available on Google Colab.
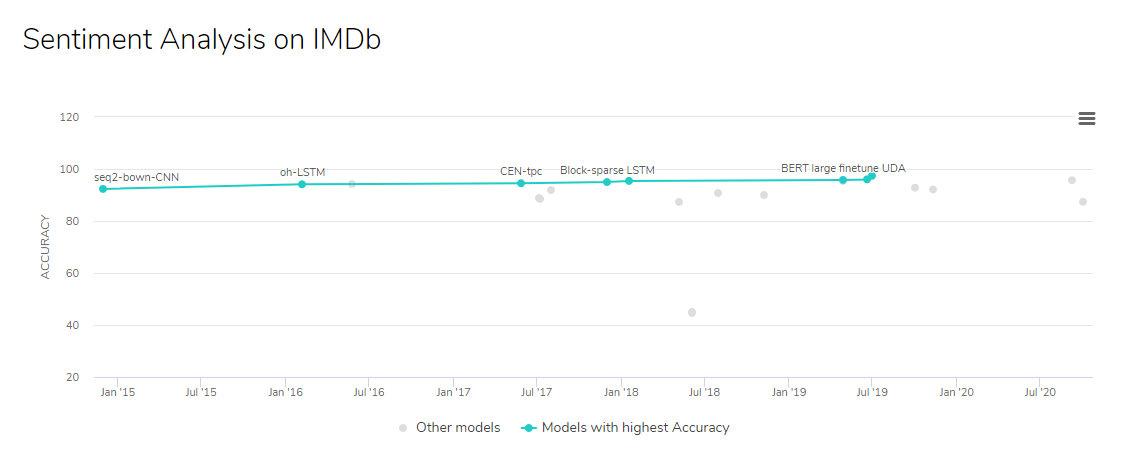
IMDb Sentiment Analysis chart on PapersWithCode
Raw dataset publications
When someone publishes a new dataset library, the most straightforward thing to do is to share it in the research team’s webpage. For example, the IMDB Sentiment analysis dataset is published by a team of Stanford researchers and available at their own webpage: Large Movie Review Dataset. In case of a scientific publication, it usually comes with a published article: see Maas et al. [1] for example.
The original publication page of the IMDB Sentiment Dataset
I think, the two major problems with this are: 1) it is hard to find, especially, if you are an early-carrier scientist; 2) there is no standardised format to store the data and using a new dataset must come with a specific preprocessing step.
#machine-learning #nlp #tutorial #tensorflow #artificial-intelligence
