Remember our objective? We are trying to create a recommendation system for cities in the US! Why? To better inform people of which cities they should be considering taking a job in, or moving to for any reason!
In this part, I explain how the recommender system works based on the data scraped in Part 1, which was later preprocessed, explored, and modeled — as explained in Part 2 — to create this final data file. Then I’ll show some of the results and explain how you can use it yourself!
Recommender Systems — Review
There are two main methods to build a recommender system — a system that suggests relevant items to users:
- Collaborative Filtering: uses recorded interactions between users and items to produce recommendations. This implies that a user’s behavior is indicative of a similar user’s behavior. Example: Siri likes oranges and apples (pun intended); we know that Alexa likes oranges; hence we will recommend Alexa an apple.
- Content-based: uses information about users and/or items to produce a recommendation based on the similarity between such items. Example: Daniel likes Avicii; Avicii’s music is similar to Martin Garrix’s; therefore I will recommend Martin Garrix to Daniel.
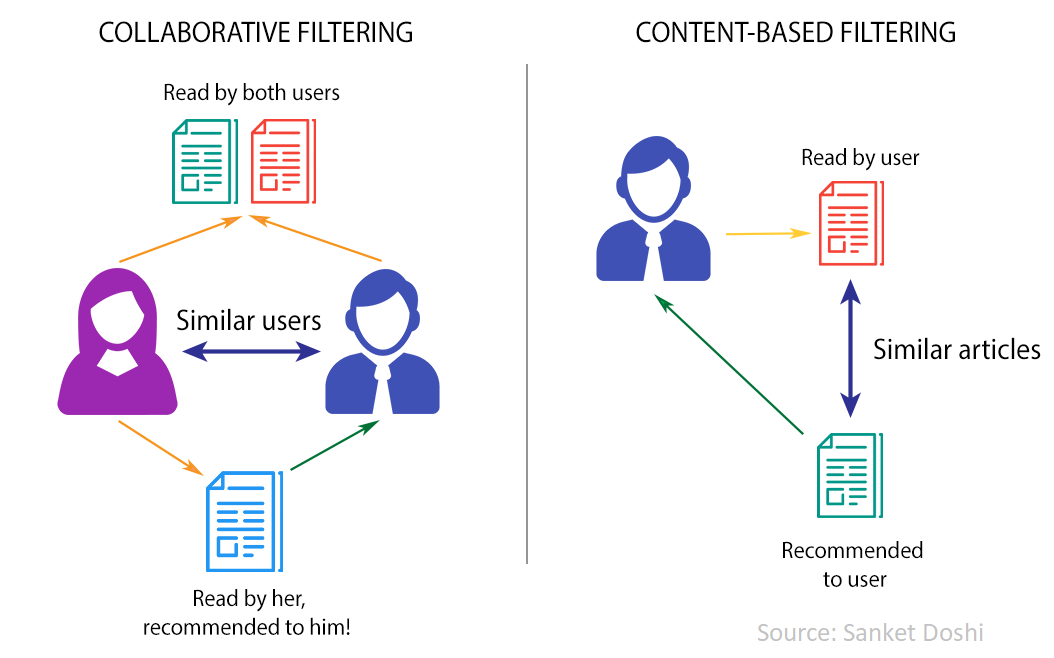
Main recommendation methods
You may be asking yourself, can you mix both systems so that it leverages user and content input? Absolutely! Hybrid recommender systems are the most commonly used in companies, and can apply a wide variety of methods including deep learning, residual learning, autoencoders, and Restricted Boltzmann Machines! If you want to learn more about recommender systems, check out this Udemy course.
There’s a good number of collaborative filtering recommender systems used on cities, my favoritve article about it being this one (super straightforward!). So, for the purposes of the city recommender, I built a content-based recommender system.
#recommender-systems #city-living #job-hunting #moving #recommendations