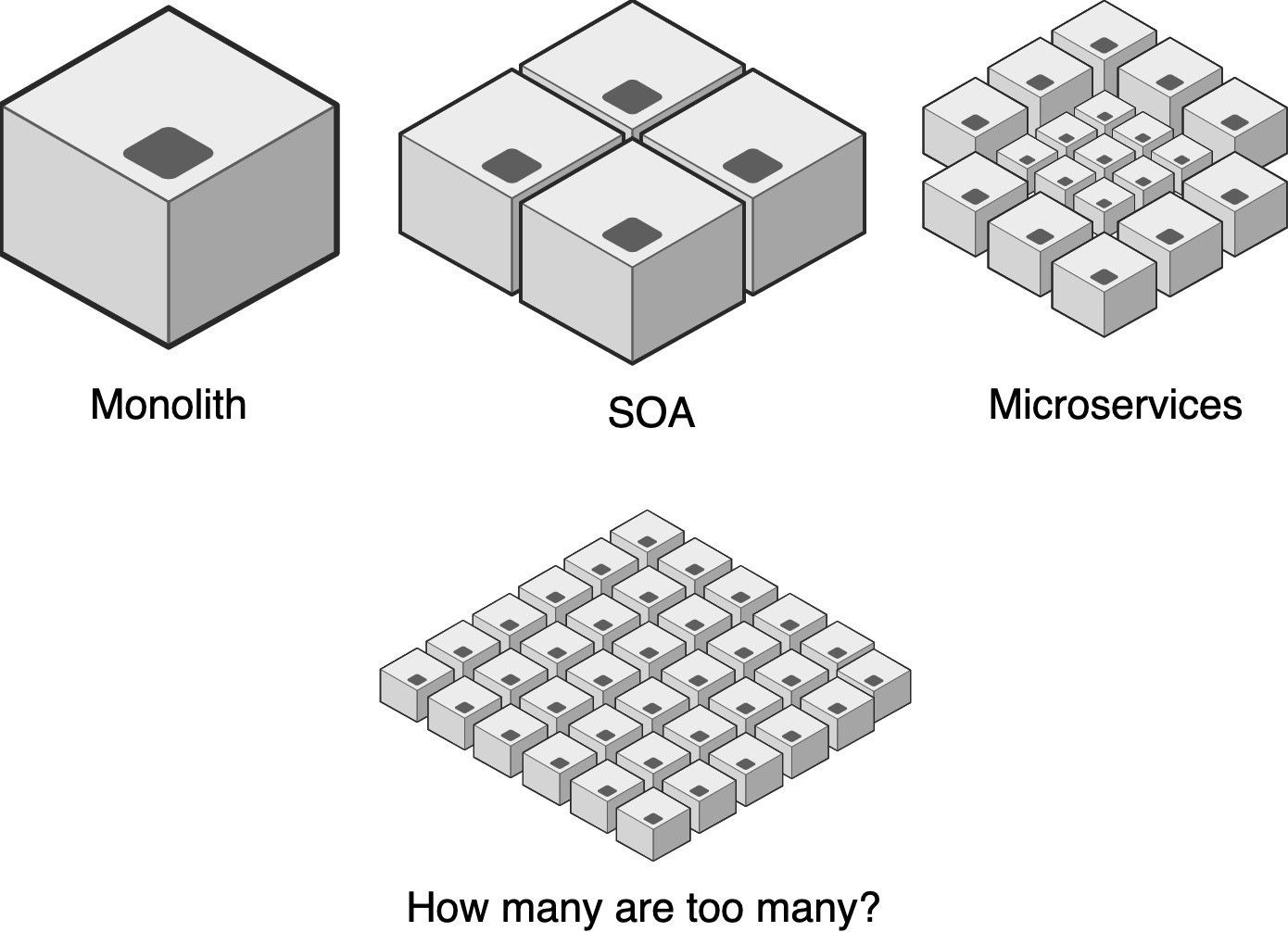
When using microservices architecture to build a successful product, a product that needs to rapidly grow, sooner or later, you realize that your system becomes “deep.”
The depth of a system can be considered as the number of microservices layers in the application stack.
Today’s forefront cloud technologies, such as Service Mesh, Containers, and Serverless computing, enable teams to easily add many microservices layers to their system.
RELATED SPONSORED CONTENT
Kubernetes Up & Running – Download the eBook (By O’Reilly)
Database Requirements for Microservices
Knative Cookbook (By O’Reilly): Building Effective Serverless Applications with Kubernetes and OpenShift – Download Now
The Business Bottleneck – Download the eBook (By O’Reilly)
From Docker to Kubernetes: Container Networking 101 (By O’Reilly)
RELATED SPONSOR

**NGINX Plus is the complete application delivery platform for the modern web. **Start your 30 day free trial.
A microservice within such a system is not actually independent - it relies on other microservices and vice versa.
When microservices communication grows deep, it complicates the company’s ability to quickly diagnose errors or performance bottlenecks.
Therefore, deep systems are a serious challenge for R&D teams who want to sustain resilience, fault-tolerance, and performance.
Without the right mindset and the right tooling, the product and it’s customers will be jeopardized.
It’s possible to build complex systems, with deep chains of microservices, without compromising on resilience.
Here are 3 ingredients that can help you nourish resilience in deep systems.
1. Service granularity
Don’t go with the hype; correspond to a real business capability.
When designing complex applications using microservice architecture, we’re looking to define a set of cohesive and loosely-coupled services. One of the biggest questions in that regard is, how will we break down our application into microservices?
Because microservices architecture essentially follows the Unix philosophy of “Do one thing and do it well,” you could simply say that each atomic function should be a microservice (i.e. the hype). While in theory it sounds perfect, simply following that philosophy can create an enormous amount of microservices. Are you going to be successful in maintaining that many services effectively?
I’m going to provision the “integer” service in us-west-1
Said once a hyped developer
In reality, we found that defining microservices that correspond to a real business capability will result in a sane amount of self-contained pieces of business functionality. Those pieces can still be very cohesive, loosely coupled, scale well, be testable, built, and owned by a small enough team. All of which are the pillars of microservices.
Moreover, it’s a common practice to avoid code duplications in multiple microservices by creating a shared library, i.e. DRY (Don’t Repeat Yourself). DRY is an important concept. Yet, sometimes too hyped. In reality, we found that sometimes shared libraries couple our microservices to each other, reducing the effectiveness of the isolation and independence between the microservices. It also slows down teams from making changes, since they are not always fully aware of the usage patterns of other teams. In fact, balancing microservices granularity goes hand in hand with balancing the right amount of shared libraries. Both shared libraries and code duplication are a burden in hyper-granular microservices architecture. But when keeping a balanced microservice granularity, the price of code duplication can pay off as increased independence.
#distributed tracing #distributed systems #microservices #complex systems #architecture & design #development #article