How To Create a Better Command Line JSON/CSV Converter in Python
Problems with the Original
The original script made the assumption that only two file types (CSV/JSON) were involved. If one was imported then it would be converted to the second and vice versa.
But what happens when we add a third file type?
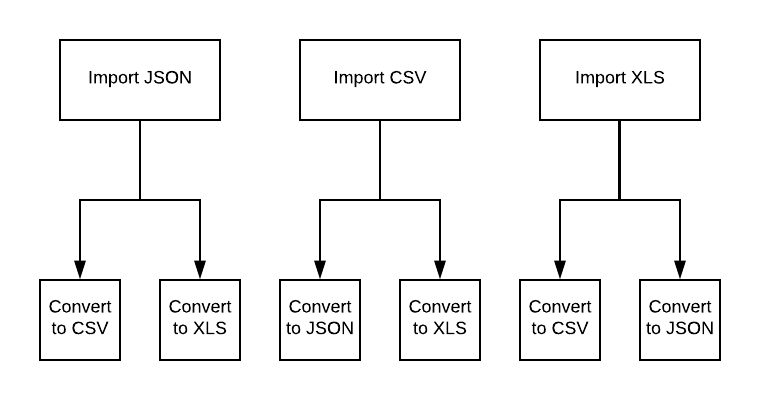
Each additional file type would require a function to do the import, then new conversion functions for each supported file type. Deciding on a standard data type for the converter was necessary for scalability.

Now, whenever a new file type is added to the converter, only two functions need to be made — converting to the standard format and converting from the standard format.
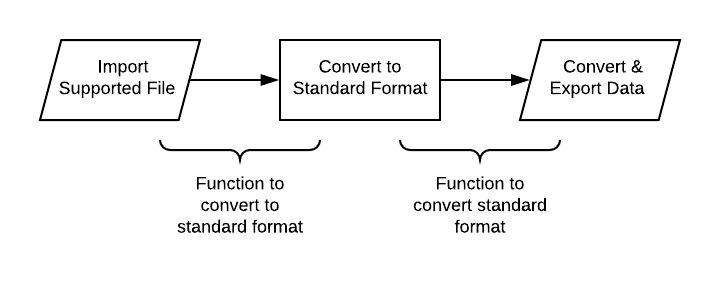
The Skeleton
Given our design decisions from above, we create a skeleton with the necessary import/export functions and comments to outline the execution.
import os
import csv
import json
import xlsxwriter
from collections import OrderedDict
import math
def main():
# supported file types
# prompt user for file name
# attempt to import based on file name
# prompt user for export file name
# export data
################################
# IMPORT FUNCTIONS
################################
def importJSON(f):
pass
def importCSV(f):
pass
################################
# EXPORT FUNCTIONS
################################
def exportJSON(data,filename):
pass
def exportCSV(data,filename):
pass
#----------
if __name__ == "__main__":
main()
Here’s the main() function fleshed out:
def main():
# supported file types
supported_file_types = (
"json",
"csv"
)
# prompt user for file name
while True:
filename = input(f"Enter a file to load ({','.join(supported_file_types)}): ").strip()
if os.path.isfile(filename) == False:
print(">> Error, file does not exist")
elif os.path.basename(filename).split(".")[1].lower() not in supported_file_types:
print(">> Error, file type is not supported.")
else:
break
# attempt to import based on file name
print("Attempting to load file...")
try:
f = open(filename)
file_type = os.path.basename(filename).split(".")[1].lower()
if file_type == "json":
imported_data = importJSON(f)
elif file_type == "csv":
imported_data = importCSV(f)
if imported_data is False:
raise Exception(">> Error, could not load file, exiting...")
except Exception as e:
print(e)
else:
print(f">> File loaded, {len(imported_data)} records imported...")
# prompt user for export file name
while True:
export_filename = input(f"Enter the output file name ({','.join(supported_file_types)}): ").strip().lower()
if os.path.basename(export_filename).split(".")[1].lower() not in supported_file_types:
print(">> Error, file type is not supported.")
elif os.path.isfile(export_filename) == True:
print(">> Error, file already exists")
else:
converted_file_type = os.path.basename(export_filename).split(".")[1].lower()
break
# export data
if converted_file_type == "json":
data_size = exportJSON(imported_data, export_filename)
elif converted_file_type == "csv":
data_size = exportCSV(imported_data, export_filename)
if data_size > 1000000:
print(f">> Records exported to: {export_filename} <{math.floor(data_size/1000)/10} MB>")
elif data_size > 0:
print(f">> Records exported to: {export_filename} <{math.floor(data_size/10)/10} KB>")
else:
print(">> Error, no file exported...")
Planning for the future, I added in a tuple to hold the supported file types for easy validation. I chose to use f-string literals for transposing variables because there were not too many insertions and the strings were still easily read when scanning the code.
Importing CSV and JSON Files
The import functions are relatively straightforward and unchanged from the original converter, with the exception of some small performance tweaks.
def importJSON(f):
try:
data = json.load(f,object_pairs_hook=OrderedDict)
if isinstance(data,OrderedDict):
data = [data]
return data
except Exception as e:
print(e)
return False
def importCSV(f):
try:
data = list(csv.reader(f))
keys = data[0]
converted = []
for line in data[1:]:
obj = OrderedDict()
for key in keys:
if len(line[key]) > 0:
obj[key] = line[key]
else:
obj[key] = None
converted.append(obj)
return converted
except Exception as e:
print(e)
return False
When importing CSV, I opted for directly iterating over the list instead of using for i in range(len(data)). Additionally, I chose to use slice notation to remove the first index. When importing JSON, OrderedDicts are used to preserve the arrangement of the key-value pairs in the event we want to import and export in the same file format, effectively creating an identical copy.
Exporting CSV and JSON Files
As the standard format for this convert is JSON, exporting JSON is very direct. As per the design of this converter, when exporting CSV the first step is to convert from JSON.
def exportJSON(data,filename):
try:
with open(filename, 'w') as outfile:
json.dump(data, outfile,indent=2)
return os.path.getsize(filename)
except Exception as e:
print(e)
return False
def exportCSV(data,filename):
try:
keys = set([
cell
for line in data
for cell in line
])
# map data in each row to key index
converted = []
converted.append(keys)
for line in data:
row = []
for key in keys:
if key in line:
if isinstance(line[key],(list,OrderedDict,dict)):
continue # skip nested data structures
else:
row.append(line[key])
else:
row.append(None)
converted.append(row)
with open(filename, 'w') as outfile:
writer = csv.writer(outfile)
writer.writerows(converted)
return os.path.getsize(filename)
except Exception as e:
print(e)
return False
I like to set an indent value when using json.dump() to avoid a long one-line dump, which can slow down some editors, like Atom. The CSV export uses list comprehension instead of nested for loops for a nice performance and pythonic improvement.
Conclusion
I was happy to share this with the community. It’s a great example of continual improvement and beginner optimization. Visit the repository to see the final result and keep up to date with new additions to the tool. Feel free to use and contribute to it, or fork it and make it your own.
Repository: https://github.com/jhsu98/data-converter
Thank you !
#Python #Data Science #Programming #Technology #Webdev
