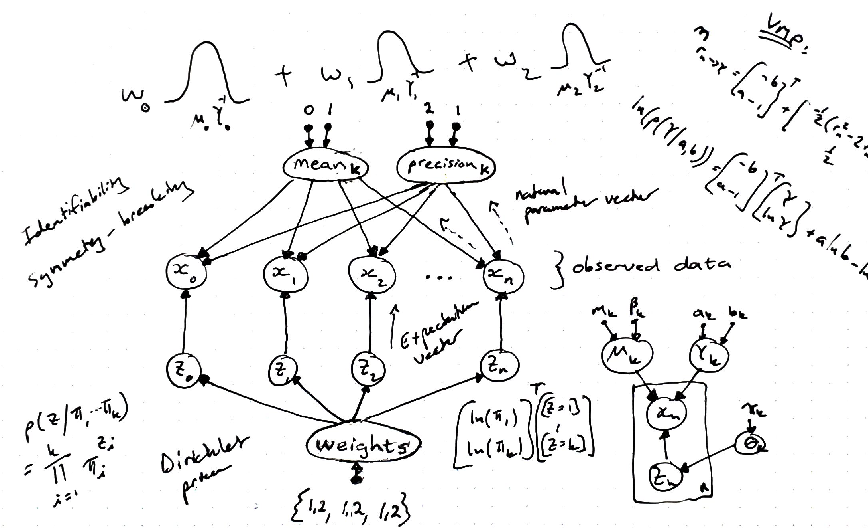
This post provides a brief introduction to Bayesian Gaussian mixture models and share my experience of building these types of models in Microsoft’s Infer.NET probabilistic graphical model framework. Being comfortable and familiar with k-means clustering and Python, I found it challenging to learn c#, Infer.NET and some of the underlying Bayesian principles used in probabilistic inference. That being said, there is a way for Python programmers to integrate .NET components and services using pythonnet, which I will cover in a follow-up post. My hope is that the content of this post will save you time, remove any intimidation that the theory may bring and demonstrate some of the advantages of what is known as the Model-based machine learning (MBML) approach. Please follow the guidelines provided in the Infer.NET documentationto get set up with the Infer.NET framework.
Bayesian Gaussian mixture models constitutes a form of unsupervised learning and can be useful in fitting multi-modal data for tasks such as clustering, data compression, outlier detection, or generative classifiers. Each Gaussian component is usually a multivariate Gaussian with a mean vector and covariance matrix, but for the sake of demonstration we will consider a less complicated univariate case.
We begin by sampling data from a univariate Gaussian distribution and store the data in a .csv file using Python code:
## generate random samples from Gaussian distributions #
import pandas as pd
import numpy as np
import scipy.stats as stats
import matplotlib.pyplot as plt
## number of data points
N = 100
true_mean_0 = 1
true_mean_1 = 3
true_mean_2 = 5
true_precision_0 = 10
true_precision_1 = 10
true_precision_2 = 10
def sample(component):
if component == 0:
return np.random.normal(true_mean_0, np.sqrt(1 / true_precision_0), 1)[0]
if component == 1:
return np.random.normal(true_mean_1, np.sqrt(1 / true_precision_1), 1)[0]
else:
return np.random.normal(true_mean_2, np.sqrt(1 / true_precision_2), 1)[0]
## weight distribution p can be changed to create more Gaussian component data
mask = np.random.choice([0, 1, 2], N, p=[0, 0, 1])
data = [sample(i) for i in mask]
df = pd.DataFrame(data)
df.to_csv('data.csv', sep=',', header=False, index=False)
#probabilistic-programming #gaussian-mixture-model #bayesian-inference