Create an Anime Database using python and urllib & BeautifulSoup libraries
Tejas-Haritsa-vk/Creating_Anime_Database_With_Web_Scraping
For those of you who might have missed out on Part-I Introduction:
Creating Anime Database With Web Scraping-Introduction
Create an Anime Database using python and urllib & BeautifulSoup libraries
Web Scraping Tutorial
- Before we begin, For this tutorial we’ll be using Google Chrome Web Browser.
- Link for Google Chrome: “https://www.google.com/intl/en/chrome/" for those who need it.
- you will also need the following libraries installed:
#importing required libraries
import urllib from urllib.request
import Request, urlopen from bs4
import BeautifulSoup as bs
import re
import csv
Topics Covered in this post: How to inspect & analyze a webpage for web scraping
First thing is first we need a website to start scraping the data from, I’ll be using “https://www4.animeseries.io/" as an example in this post.
base_url = "https://www4.animeseries.io"
#initilizing base url
url_template = https://www4.animeseries.io/search/character=special"
#initilizing url template for alphabetical search
url = url_template
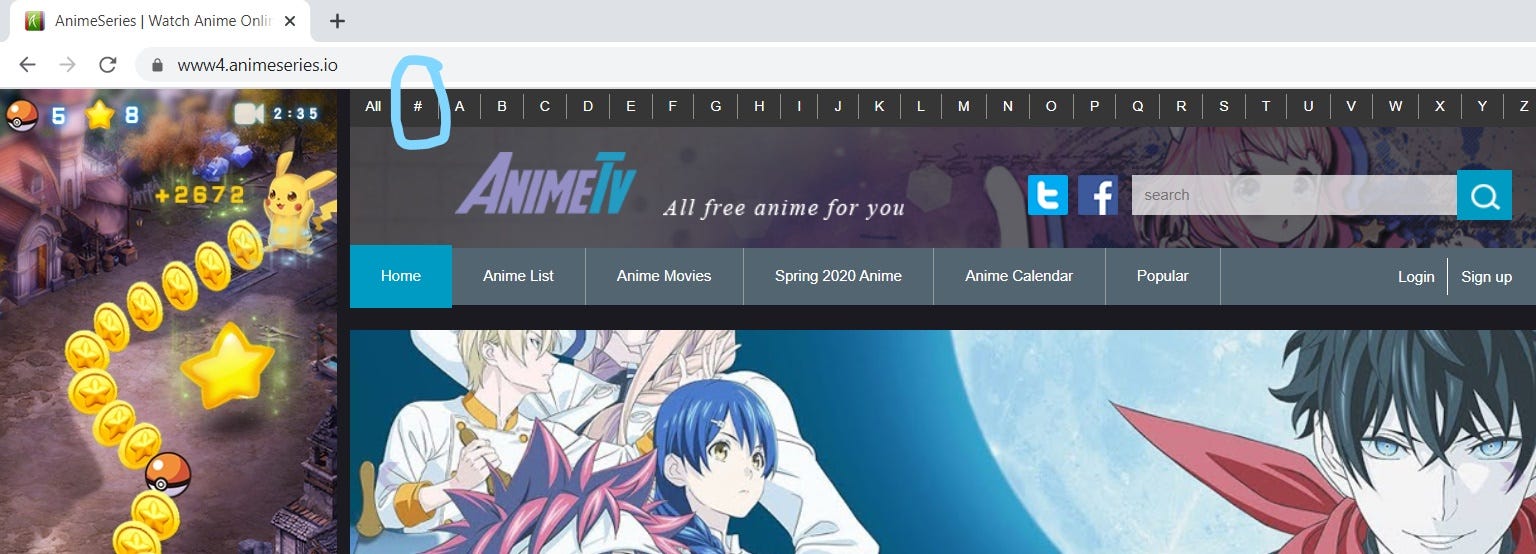
Step 1: Navigate to the said website

Step 2: Navigate & click on the “#” Charecter besides “ALL” at the top of the page
- when clicked on “#” it’ll take you to “https://www4.animeseries.io/search/character=special"
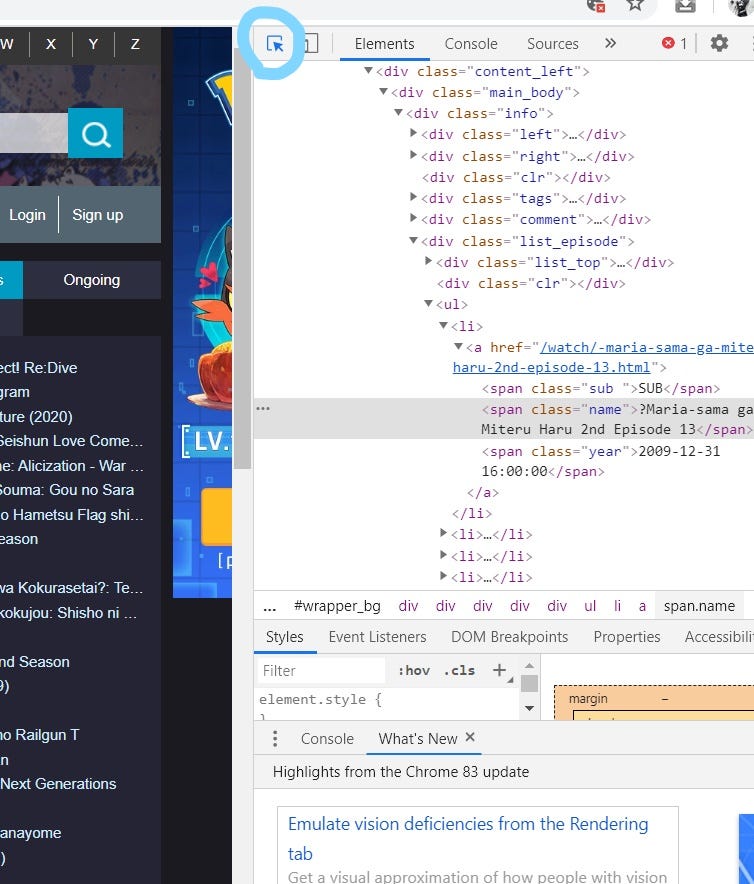
Step 3: Right-click anywhere on the screen and click on Inspect Option

Step 4: Click on “Select an element in the page to inspect it” option
- while inspecting an element pay close attention to its corresponding HTML source code and where in the hierarchy is it appearing. This will be very useful when extracting data later on through BeautifulSoup.
#Below we will be requesting the html source code from the website through the urllib module's Request function & reading it using urlopen function
#Requesting for url using Request Library
url_link = Request(url, headers={'User-Agent': 'Mozilla/5.0'})
#using headers={'User-Agent': 'Mozilla/5.0'} for setting preferred browser
url_page = urlopen(url_link).read() #reading url
url_html = bs(url_page, 'html.parser') #parsing html file using BeautifulSoup (getting the html source code)
#Familiarize yourself with the HTML Structure to better navigate through it
url_html # viweing the raw HTML source code
- raw HTML source code, Try to read a few lines and understand the basic structure. If you don’t get it don’t worry we’ll be covering it in detail later
#web-crawler #data-science #database #web-crawling #data-scraping #data analysis
4.75 GEEK