My interest in Artificial Intelligence and in particular in Natural Language Processing (NLP) has sparked exactly when I have learned that machines are capable of generating the new text by using some simple statistical and probabilistic techniques. In this article I wanted to share this extremely simple and intuitive method of creating Text Generation Model.
Background
As we all know, language has a sequential nature, hence the order in which words appear in the text matters a lot. This feature allows us to understand the context of a sentence even if there are some words missing (or in case if stumble across a word which meaning is unknown). Consider example below:
“Mary was scared because of the terrifying noise emitted by Chupacabra.”
Without some previous context we have no idea what “Chupacabra” indeed is, but we probably can say that we would be not happy to encounter this creature in real life.
This dependency of words inside the sentence can give us some clues about the nature of the missing word and sometimes we do not even need to know the whole context. In the example above, by looking only at “noise emitted by” we on the intuitive level can say that the following word should be a noun and not some other part of speech.
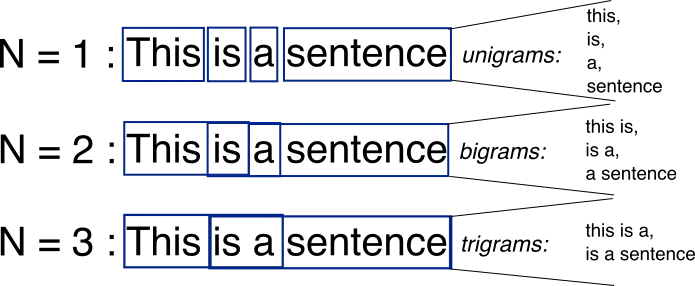
This brings us up to the idea behind the _N-Gram_s, where the formal definition is “a contiguous sequence of n items from a given sample of text”. The main idea is that given any text, we can split it into a list of unigrams (1-gram), bigrams (2-gram), trigrams (3-gram) etc.
For example:
Text: “I went running”
Unigrams: [(I), (went), (running)]
Bigrams: [(I, went), (went, running)]
As you can notice word “went” appeared in 2 bigrams: (I, went) and (went, running).
The other, more visual, way to look at it
#artificial-intelligence #language-modeling #ngrams #naturallanguageprocessing