As data scientists, we are all familiar with scikit-learn, one of the most used machine learning and data analysis libraries available in Python. I’ve personally used it, along with pandas, for the majority of my professional projects.
It is only recently, however, that I have gotten the most out of scikit-learn when I needed to build a custom regression estimator. I was pleasantly surprised at how easy it was to create a new and compatible class of estimator, and this is all due to the object-oriented design of the scikit-learn components.
In this article, I will walk you through a common data science workflow and demonstrate a use case for object-oriented programming (OOP). In particular, you will learn how to make a custom transformer object using the concept of inheritance, which allows us to extend the functionality of an existing class. Thanks to inheritance, this transformer will then easily fit into a scikit-learn pipeline to build a simple machine learning model.
A motivating example.
To illustrate things more clearly, let’s work through a practical example inspired by marketing for a retailer. Suppose I have a data set where each record represents a customer and there are measurements (i.e. features) relating to purchase recency, frequency, and monetary value. Using these features, we would like to predict whether or not the customer will join the retailer’s rewards card program. This emulates a real-world scenario where we want to predict which clients are the best targets for marketing. See a sample of the customer record data below:
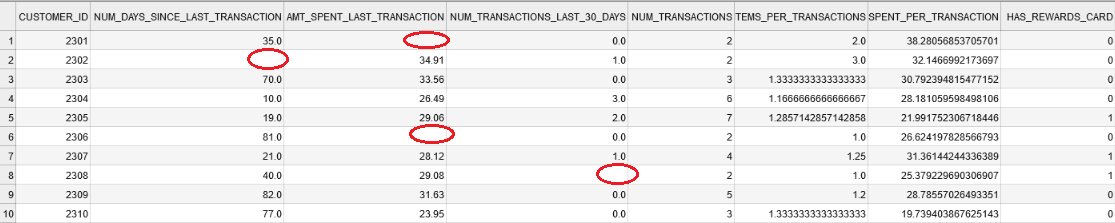
One noticeable quality of the data is missingness, the presence of missing values in the observations. These values will be rendered as NaN’s once read by pandas and will not work in our machine learning model. To build our model, we will need to impute values (i.e. substitute missing values with inferred quantities) for the missing features. While there are a number of techniques for data imputation, for the sake of simplicity let’s say we want to try either imputing the column mean or median for any missing value.
So, which statistic should we use, the mean or the median? One easy way of finding out is by trying both options and assessing which yields the best performance in a grid search, maybe by using scikit-learn’s GridSearchCV.
One mistake would be to compute the mean and median on the entire training set and then impute with those values. To be more rigorous, we need to compute these statistics on the data excluding the holdout fold. This seems complicated, but thanks to OOP, we can easily implement our own transformer via inheritance which will be compatible with scikit-learn. From there, we can plug the transformer into a scikit-learn Pipeline, an object which sequences together with a list of transformer objects along with an estimator object, to build our model.
#data-science #python