Decision Tree is one of the most widely used machine learning algorithm. It is a supervised learning algorithm that can perform both classification and regression operations.
As the name suggest, it uses a tree like structure to make decisions on the given dataset. Each internal node of the tree represent a “decision” taken by the model based on any of our attributes. From this decision, we can seperate classes or predict values.
Let’s look at both classification and regression operations one by one.
Classification
In Classification, each leaf node of our decision tree represents a **class **based on the decisions we make on attributes at internal nodes.
To understand it more properly let us look at an example. I have used the Iris Flower Dataset from sklearn library. You can refer the complete code on Github — Here.
A node’s samples attribute counts how many training instances it applies to. For example, 100 training instances have a petal width ≤ 2.45 cm .
A node’s value attribute tells you how many training instances of each class this node applies to. For example, the bottom-right node applies to 0 Iris-Setosa, 0 Iris- Versicolor, and 43 Iris-Virginica.
And a node’s gini attribute measures its impurity: a node is “pure” (gini=0) if all training instances it applies to belong to the same class. For example, since the depth-1 left node applies only to Iris-Setosa training instances, it is pure and its gini score is 0.
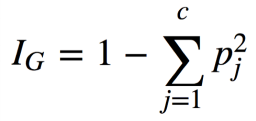
Gini Impurity Formula
where, pⱼ is the ratio of instances of class j among all training instances at that node.
Based on the decisions made at each internal node, we can sketch decision boundaries to visualize the model.
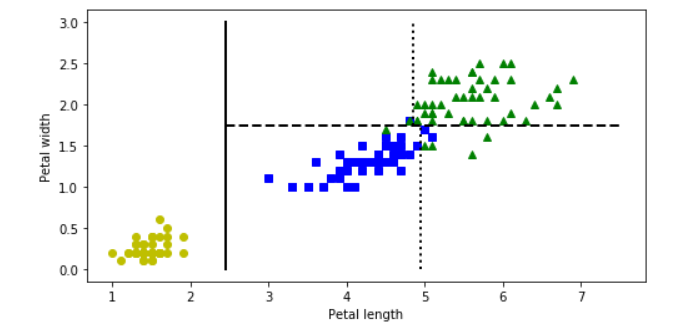
But how do we find these boundaries ?
We use Classification And Regression Tree (CART) to find these boundaries.
CART is a simple algorithm that finds an attribute _k _and a threshold _t_ₖat which we get a purest subset. Purest subset means that either of the subsets contain maximum proportion of one particular class. For example, left node at depth-2 has maximum proportion of Iris-Versicolor class i.e 49 of 54. In the _CART cost function, _we split the training set in such a way that we get minimum gini impurity.The CART cost function is given as:

After successfully splitting the dataset into two, we repeat the process on either sides of the tree.
We can directly implement Decision tree with the help of Scikit learn library. It has a class called DecisionTreeClassifier which trains the model for us directly and we can adjust the hyperparameters as per our requirements.

#machine-learning #decision-tree #decision-tree-classifier #decision-tree-regressor #deep learning
