We always say “Garbage in Garbage out” in data science. If you do not have a good quality and quantity of data, mostly likely you would not get much insights out of it. Web Scraping is one of the important methods to retrieve third party data automatically. In this article, I will be covering the basics of web scraping and use two examples to illustrate the 2 different ways to do it in Python.
What is Web Scraping
Web Scraping is an automatic way to retrieve unstructured data from website into structured data for analysis. For example, if you want to analyse what kind of face mask can sell better in Singapore, you may want to scrape all the face mask information on E-Commerce website like Lazada.
Can you scrape from all the websites?
Scraping makes the website traffic to spike and may cause breakdown of the website server. Thus, not all of the websites allow people to scrape. How do you know which websites are allowed or not? You can look at ‘robots.txt’ file of the website. You just simply put robots.txt after the url that you want to scrape and you will see information on whether website host allow you to scrape the website.
Take Google.com for an example
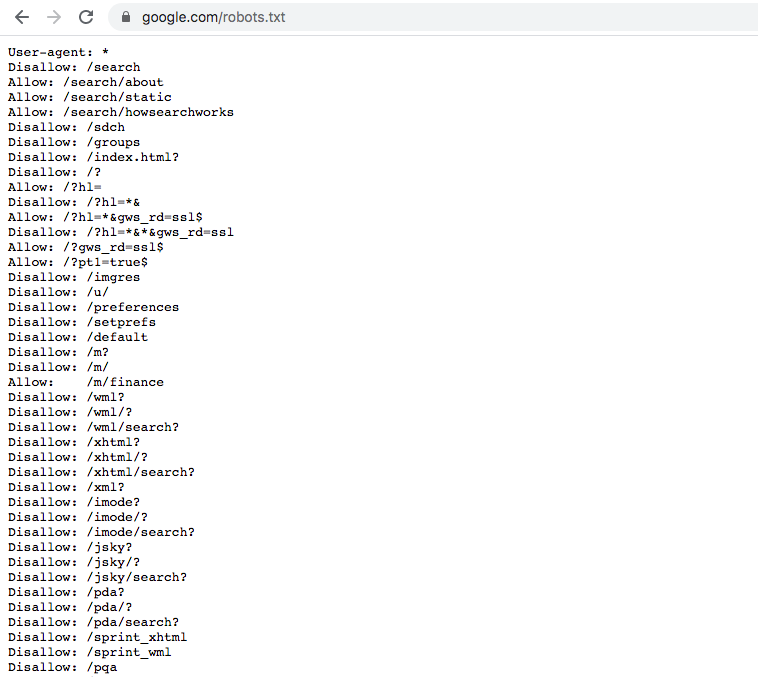
robots.txt file of Google.com
You can see that Google does not allow web scraping for many of its sub-websites. However, it allows certain path like ‘/m/finance’ and thus if you want to collect information on finance then this is a completely legal place to scrape.
Another note is that you can see from the first row on User-agent. Here Google specifies the rules for all of the user-agents but website may give certain user-agent special permission so you may want to refer to information there.
How does web scraping work?
Web scraping just works like a bot person browsing different pages website and copy paste down all the contents. When you run the code, it will send a request to the server and the data is contained in the response you get. What you then do is to parse the response data and extract out the parts you want.
How do we do web scraping?
Alright, finally we are here. There are 2 different approaches for web scraping depending on how does website structure their contents.
Approach 1:_ If website stores all their information on the HTML front end, you can directly use code to download the HTML contents and extract out useful information._
There are roughly 5 steps as below:
- Inspect the website HTML that you want to crawl
- Access url of the website using code and download all the HTML contents on the page
- Format the downloaded content into readable format
- Extract out useful information and save into a structured format
- For information displayed on multiple pages of website, you may need to repeat step 2–4 to have the complete information.
**Pros and Cons for this approach: **It is simple and direct. However, if website front end structure changes then you need to adjust your code accordingly.
Approach 2: If website stores data in API and the website queries the API each time when user visit the website, you can simulate the request and directly query data from the API
#machine-learning #web-scraping #data-engineering #data-science #python #data analysis
